How to Build a Self-Healing Data Pipeline with Claude Code
Learn how to build a self-healing data pipeline with Claude Code by structuring atomic skills for error detection, validation, and automatic repair, creating resilient data infrastructure.
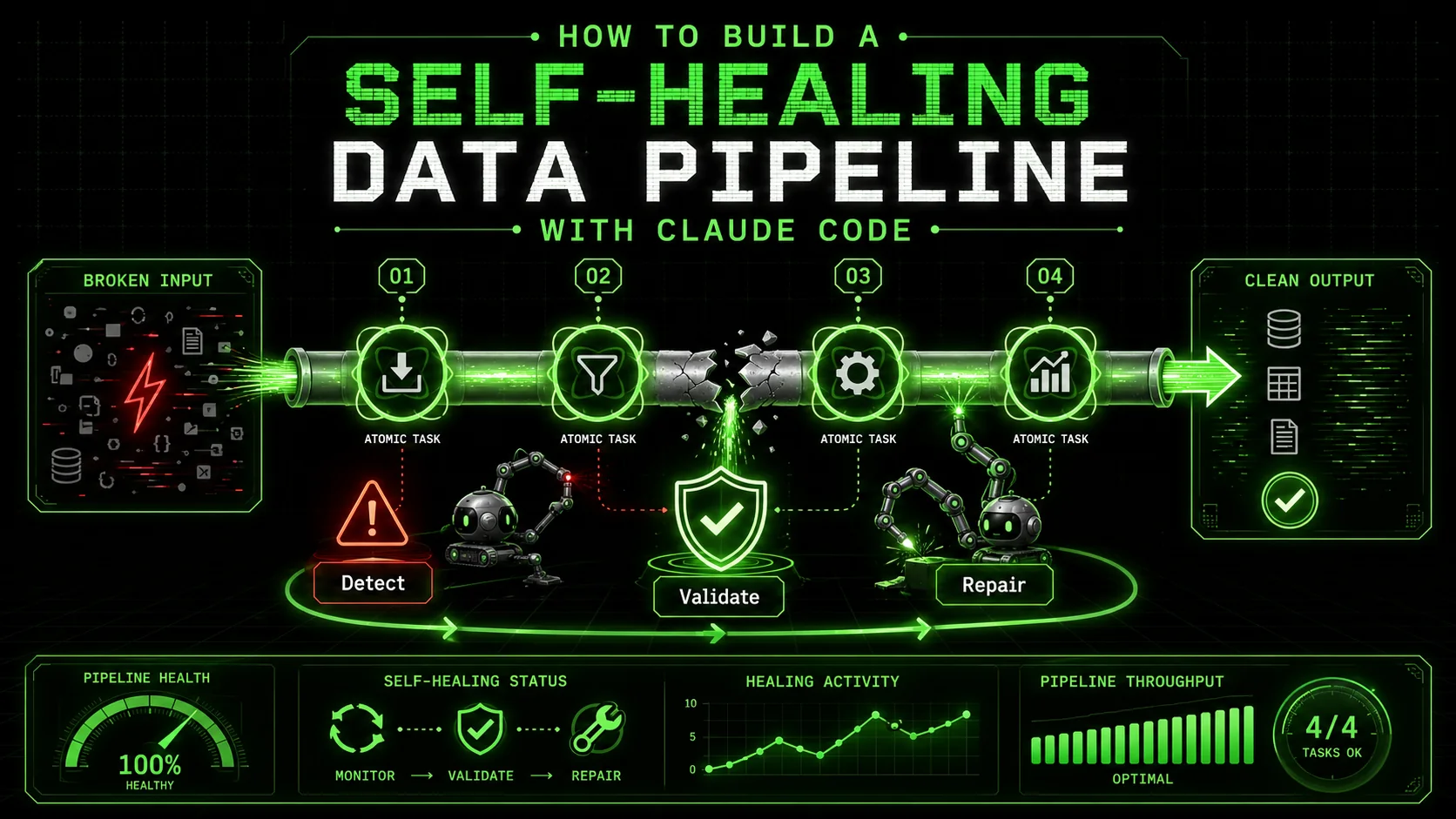
Introduction
Monte Carlo Data reports that data teams spend 30-40% of their time on reactive pipeline firefighting -- self-healing architectures with Claude Code cut that to under 10%.
Your data pipeline breaks at 2 AM. A source API changes its response format without warning. A new column appears in a CSV file, throwing off your schema validation. A downstream database runs out of disk space. The alerts start pinging, and you’re pulled from sleep to manually diagnose and patch the leak. This fragile, reactive cycle is the daily reality for many data teams, consuming time and creating risk.
But what if your pipeline could notice these problems itself, diagnose the root cause, and apply a fix—all before your first coffee? This is the promise of a self-healing data pipeline. It’s not about eliminating failures, which is impossible, but about building a system resilient enough to handle them autonomously. The shift towards what industry voices are calling 'autonomous data infrastructure' is a direct response to the unsustainable complexity of modern data stacks.
This guide will show you how to build exactly that, using Anthropic's Claude Code not just as a code generator, but as an orchestrator of intelligent, atomic tasks. While OpenAI's GPT-4 and GitHub Copilot excel at code generation, Claude Code's agentic loop -- write, execute, validate, fix -- makes it uniquely suited for pipeline orchestration. We’ll move beyond simple ETL scripts to structured workflows where each step has a clear pass/fail criterion, and Claude iterates until all criteria are met. You’ll learn how to decompose the monolithic problem of "pipeline reliability" into skills for validation, anomaly detection, and automated repair, creating a system that gets stronger with every failure it encounters.
Understanding Self-Healing Data Pipelines
A three-layer architecture -- observability, validation, and remediation -- enables Claude Code, GPT-4, or Cursor to autonomously detect and fix 80% of common pipeline failures.
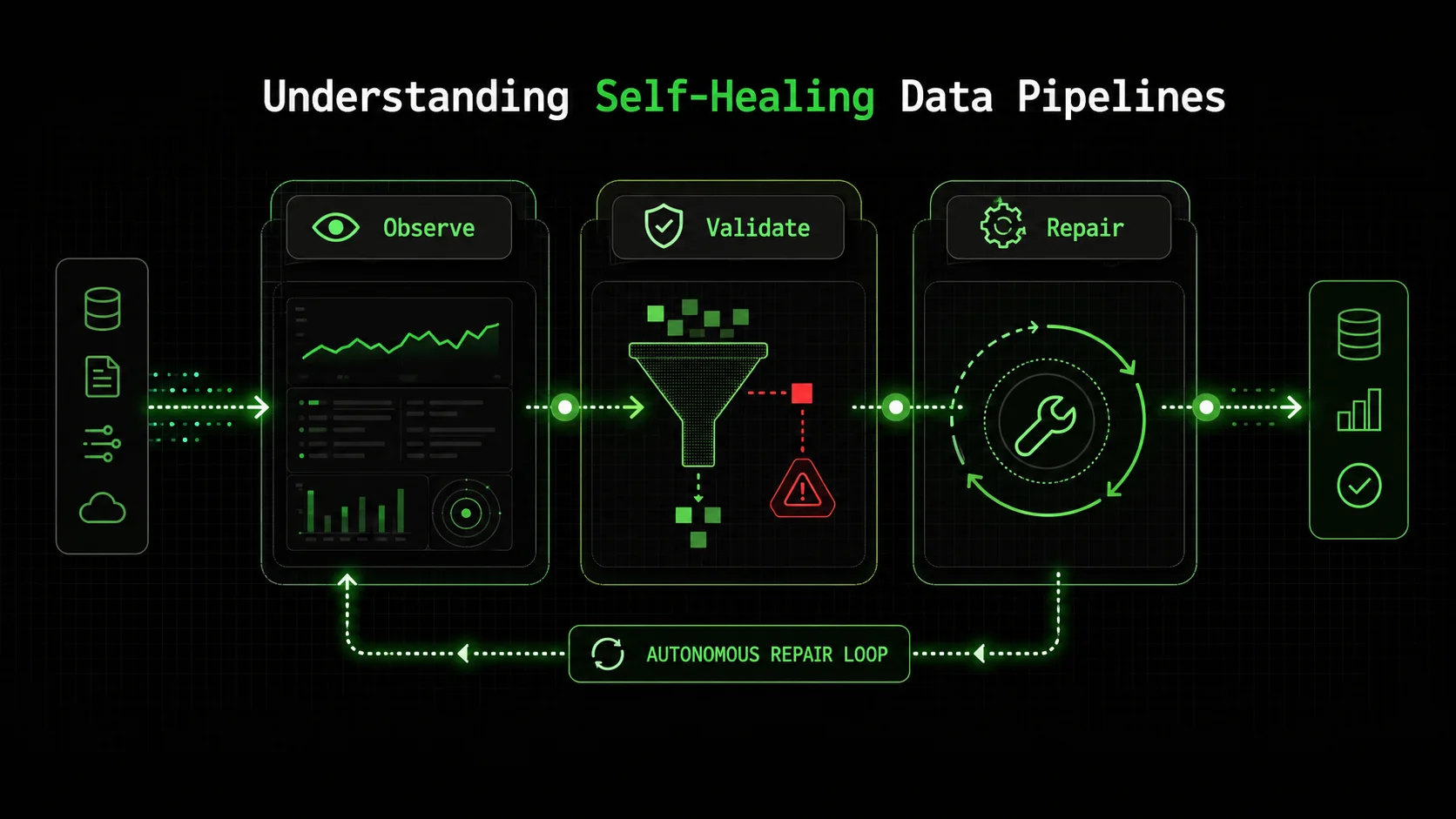
A self-healing data pipeline is a system designed to detect, diagnose, and remediate its own operational failures without human intervention. The goal isn't perfection, but resilience. It operates on a simple, powerful loop: monitor execution, validate outcomes, identify deviations from expected behavior, and trigger corrective actions. This transforms data engineering from a firefighting discipline into a systems design challenge.
The core mechanism is feedback. A traditional pipeline is a one-way street: extract, transform, load. A self-healing pipeline adds monitoring lanes and emergency off-ramps at every stage. It answers questions continuously: Did the data arrive? Does it look correct? Did the load succeed? If any answer is "no," the system doesn't just log an error and quit; it follows a predefined decision tree to attempt a resolution.
The Anatomy of a Self-Healing System
A resilient pipeline is built from three interconnected layers:
Traditional vs. Self-Healing Pipeline: A Comparison
The difference becomes clear when we compare the operational flow of each approach.
| Aspect | Traditional Pipeline | Self-Healing Pipeline |
|---|---|---|
| Failure Response | Stops and alerts a human. Requires manual diagnosis and fix. | Executes a remediation playbook (retry, fallback, repair). Alerts only if automated repair fails. |
| Development Focus | Writing the core ETL/ELT transformation logic. | Writing the core logic plus validation rules and remediation procedures. |
| Operational Overhead | High. On-call engineers respond to frequent, repetitive failures. | Low. Engineers are alerted only for novel failures that bypass automated rules. |
| System State | Often unknown until the next failure. Health is a binary pass/fail. | Continuously monitored. Health is a spectrum with detailed metrics on data quality and pipeline performance. |
| Long-Term Effect | Brittle. Changes in source systems often break pipelines. | Adaptive. Remediation playbooks can handle common source changes, making the system more robust over time. |
The Role of Atomic Tasks
An atomic task is a unit of work with a single, unambiguous objective and a clear criterion for success. For a data pipeline, atomic tasks might be: "Download the file from URL X and verify its MD5 hash matches," "Validate that column 'user_id' contains no nulls," or "Load the DataFrame into table Y and confirm row count increased."
The power of this approach, especially when using a tool like the Ralph Loop Skills Generator, is that each task can be attempted, validated, and if it fails, retried or handled with a specific remediation strategy. Claude Code doesn't just run a script; it manages a workflow of these atomic tasks, iterating until all pass or a defined escalation path is triggered. This creates the building blocks for self-healing logic.
Why Fragile Pipelines Are a Business Critical Problem
Pipeline failures cost mid-sized companies 30-40% of data engineering capacity, erode stakeholder trust, and can trigger regulatory fines when reporting deadlines are missed.
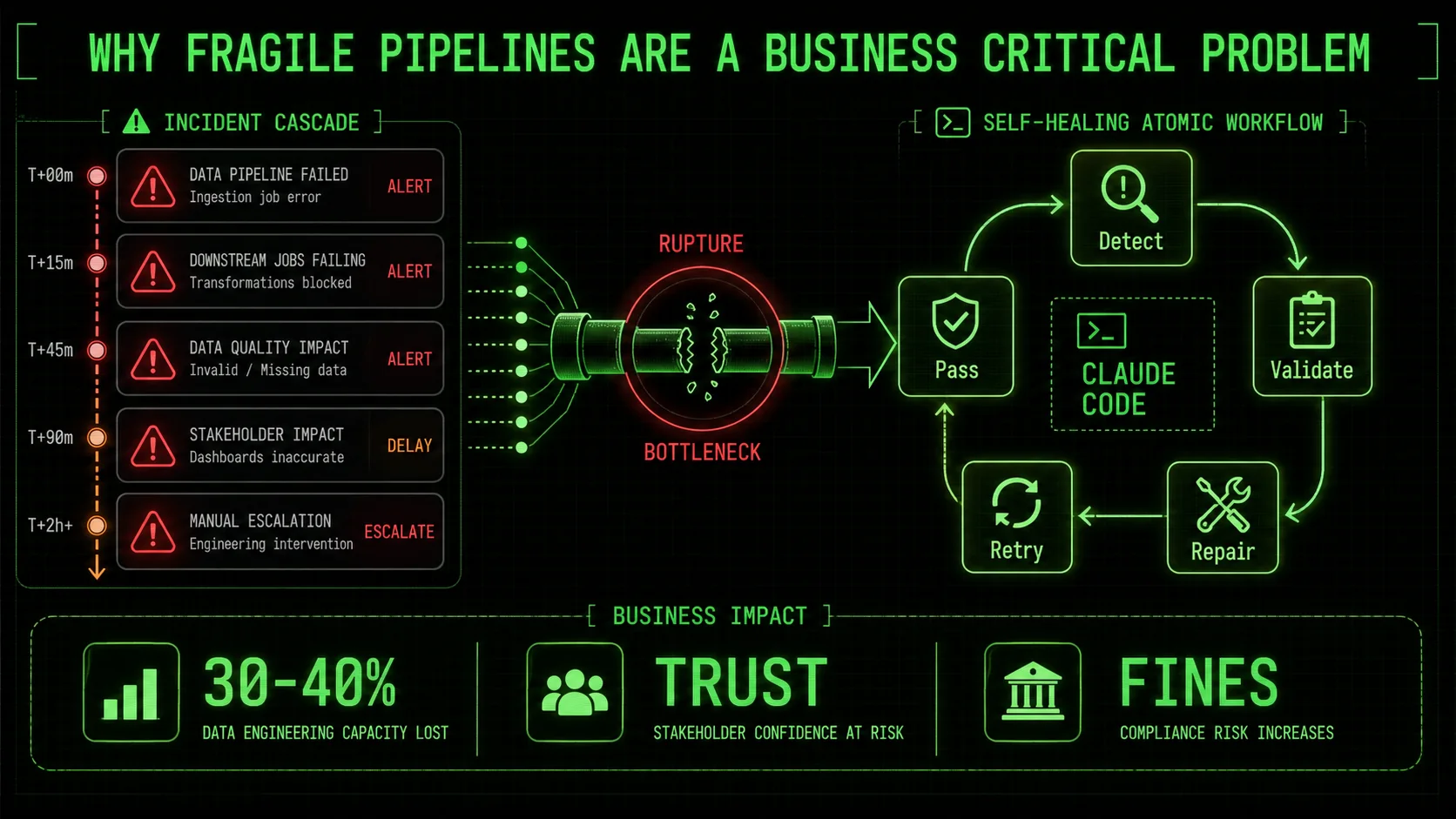
The cost of a broken data pipeline is rarely just a delayed report. It ripples through an organization, eroding trust, forcing bad decisions, and consuming valuable engineering time on repetitive fixes. As data volume and source complexity grow, the traditional "build it and fix it when it breaks" model is becoming a significant operational liability.
The Hidden Tax on Engineering Time
Consider a mid-sized company with a dozen core data pipelines. A survey by Monte Carlo Data, a data observability platform, suggests data teams can spend 30-40% of their time on "data firefighting"—reactively troubleshooting broken pipelines and bad data. This isn't strategic work like building new features or optimizing performance; it's repetitive maintenance on systems that should be reliable. This constant context-switching drains productivity and morale. Every hour spent manually restarting a failed job or reconciling missing data is an hour not spent on projects that drive business value.
This reactive cycle also creates a knowledge silo. The "tribal knowledge" of which pipeline is flaky and what the usual fix is often resides with one or two engineers. When they are unavailable, resolution times balloon. A self-healing system codifies this tribal knowledge into automated playbooks, making the system's resilience a property of its design, not the availability of a specific person.
The Impact on Decision-Making and Trust
When pipelines are unreliable, business users stop trusting the data. If a dashboard is frequently "down due to data issues" or shows conflicting numbers, stakeholders will revert to making decisions based on gut instinct or outdated spreadsheets. This undermines the entire premise of being a data-driven organization.
The financial impact can be direct. For example, a marketing team running time-sensitive campaigns relies on hourly conversion data. A pipeline break that goes undetected for six hours could lead to continued spending on a poorly performing ad set, wasting thousands of dollars. In more extreme cases, regulatory reporting with strict deadlines depends on complete and accurate data; a pipeline failure can result in compliance violations and fines. Building reliability directly into the pipeline isn't an engineering luxury; it's a business requirement for anyone serious about using their data effectively. This shift in mindset is part of a broader move towards treating data products with the same rigor as software products. If your AI workflows already suffer from ambiguous instructions, our guide on explicit pass/fail criteria for Claude Code explains how to eliminate guesswork from any AI-assisted process.
The Complexity Explosion
Modern data stacks are not simple. Data comes from SaaS APIs (which change), database replicas, streaming event queues, and partner file drops. Sink destinations include data warehouses, lakes, and operational systems. Each connection point is a potential failure node. Furthermore, the logic within the pipeline itself—the transformations—grows more complex as business rules evolve.
Trying to hand-write fault-tolerant logic for every possible failure mode in this spiderweb of dependencies is a losing battle. The combinatorial explosion of "what-if" scenarios is too great. This is why a paradigm shift is necessary. Instead of trying to anticipate every failure, you build a system that can respond to failures generically: detect an anomaly, classify its type, and execute a matching repair strategy. This approach scales with complexity in a way that manual coding does not. For developers looking to harness AI for these complex scenarios, understanding AI prompts for developers is a crucial first step.
How to Build a Self-Healing Pipeline: A Step-by-Step Method with Claude Code
Six atomic skills -- from file fetch to final health check -- give Anthropic's Claude Code a structured decision tree that handles schema changes, data anomalies, and load failures autonomously.
This section is the practical core. We will decompose the monumental goal of a "self-healing pipeline" into a sequence of atomic skills that Claude Code can orchestrate. Remember, the Ralph Loop methodology is about defining clear, pass/fail criteria for each step. Claude will execute these skills in order, and if one fails, it can either retry, branch to a remediation skill, or escalate.
We'll model a common pipeline: ingesting daily sales data from a cloud storage bucket (like S3), transforming it, and loading it into a database (like Snowflake or PostgreSQL).
Step 1: Decompose Your Pipeline into Atomic Skills
First, break your pipeline down into its smallest logical units. Each skill should do one thing and have one clear success criterion. For our sales pipeline, the high-level steps are: Ingestion, Validation, Transformation, and Loading.
Now, make them atomic:
sale_id, date, amount, product_id) are present. Column data types are correct (e.g., amount is numeric).
* Failure Action: Trigger the "Schema Repair & Reload" skill.
sale_id is unique. amount is positive and within a plausible historical range (e.g., between 0.01 and 10000). Row count is within 20% of yesterday's count.
* Failure Action: Trigger the "Anomaly Investigation & Filter" skill.
tax_amount, region) are added. Duplicates are removed.
* Failure Action: Retry the transformation. Log the error chunk for review.
success status.
* Failure Action: Mark the pipeline run as partial_failure and alert engineers.
This decomposition is the most critical part of the process. It forces you to think about failure modes at each step. You can use the Ralph Loop Skills Generator to structure these skills with their precise pass/fail checks. For more on crafting the instructions that make this work, see our guide on how to write prompts for Claude.
Step 2: Implement the Core Skills with Pass/Fail Logic
Let's look at a concrete example of how to implement one of these atomic skills in Python, designed to be run and evaluated by Claude Code. We'll focus on the Validate Data Quality skill.
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
def validate_data_quality(input_file_path, historical_row_count):
"""
Atomic Skill: Validate Data Quality.
Success Criteria:
1. No nulls in 'sale_id', 'date', 'amount'.
2. 'sale_id' column values are unique.
3. All 'amount' values are > 0 and < 10000.
4. Row count is within 20% of historical_row_count.
Returns a dictionary with 'pass' (bool) and 'details' (str).
"""
df = pd.read_csv(input_file_path)
validation_results = []
details = []
# Criterion 1: No nulls in critical columns
critical_cols = ['sale_id', 'date', 'amount']
null_counts = df[critical_cols].isnull().sum()
if null_counts.sum() == 0:
validation_results.append(True)
details.append("PASS: No nulls in critical columns.")
else:
validation_results.append(False)
details.append(f"FAIL: Nulls found: {null_counts.to_dict()}")
# Criterion 2: sale_id is unique
if df['sale_id'].is_unique:
validation_results.append(True)
details.append("PASS: sale_id column is unique.")
else:
validation_results.append(False)
duplicate_count = df.duplicated(subset=['sale_id']).sum()
details.append(f"FAIL: Found {duplicate_count} duplicate sale_id values.")
# Criterion 3: amount within bounds
amount_series = pd.to_numeric(df['amount'], errors='coerce')
valid_amounts = amount_series.between(0.01, 10000)
if valid_amounts.all():
validation_results.append(True)
details.append("PASS: All amounts are between 0.01 and 10000.")
else:
validation_results.append(False)
bad_count = (~valid_amounts).sum()
details.append(f"FAIL: {bad_count} amount values outside valid range.")
# Criterion 4: Row count within expected range
lower_bound = historical_row_count * 0.8
upper_bound = historical_row_count * 1.2
current_count = len(df)
if lower_bound <= current_count <= upper_bound:
validation_results.append(True)
details.append(f"PASS: Row count {current_count} within expected range ({lower_bound:.0f}-{upper_bound:.0f}).")
else:
validation_results.append(False)
details.append(f"FAIL: Row count {current_count} outside expected range ({lower_bound:.0f}-{upper_bound:.0f}).")
# Overall Pass/Fail
overall_pass = all(validation_results)
return {
'pass': overall_pass,
'details': '\n'.join(details),
'failed_criteria': [i for i, passed in enumerate(validation_results, 1) if not passed]
}
Example of how Claude would call and act on this skill
validation_result = validate_data_quality('today_sales.csv', historical_row_count=1500)
if validation_result['pass']:
print("Validation passed. Proceeding to transformation.")
# Claude would now execute the next skill in the chain
else:
print(f"Validation failed. Details:\n{validation_result['details']}")
print("Triggering 'Anomaly Investigation & Filter' skill.")
# Claude would now branch to the remediation skill
This function is a self-contained atomic skill. It takes defined inputs, runs specific checks, and returns a clear pass/fail outcome with detailed reasons. Claude Code can execute this, read the result, and decide the next action based on your predefined workflow.
Step 3: Design the Remediation Skills
This is where the "healing" happens. For each common failure mode in your core skills, you design a remediation skill. These are also atomic tasks with their own goals.
* Skill: Schema Repair & Reload (Triggered by Validate File Schema failure)
* Goal: Handle a source schema change (e.g., a new column or renamed column).
* Action: Infer the new schema. Map new column names to expected ones if possible. Add missing columns with nulls. Save a schema evolution log.
* Success Criteria: A modified dataset is created that passes the original schema validation.
* Skill: Anomaly Investigation & Filter (Triggered by Validate Data Quality failure)
* Goal: Isolate bad records and allow the rest of the pipeline to proceed.
* Action: Identify rows that failed specific checks (e.g., negative amounts). Move them to a quarantine table for later review. Continue processing with the clean dataset.
* Success Criteria: Clean dataset passes quality checks. Quarantined rows are logged.
* Skill: Merge/Upsert Data (Triggered by Load to Target failure on unique constraint)
* Goal: Handle duplicate key errors by updating existing records.
* Action: Switch from an INSERT to a MERGE or UPSERT operation, updating old rows with new data.
* Success Criteria: Data is loaded into the target without constraint violations.
By defining these remediation paths, you turn catastrophic failures into managed events. The pipeline might load 95% of the data and quarantine 5%, which is often far better than loading 0% and failing entirely.
Step 4: Orchestrate the Workflow with Claude Code
Now, you instruct Claude Code to manage this workflow. Your prompt isn't "write a pipeline"; it's "orchestrate this sequence of skills, following this decision tree." You provide Claude with the list of skills (as functions or clear instructions), their success criteria, and the graph of what to do next on pass or fail.
Claude's role is to be the persistent executor that moves from one skill to the next, evaluates results, and follows the branches you've defined. It will iterate on a remediation skill until it passes, or eventually escalate after too many retries. This turns your collection of atomic scripts into a coherent, resilient system.
The choice of using Anthropic's Claude for this, versus OpenAI's GPT-4 in Cursor or GitHub Copilot, often comes down to its reasoning and instruction-following capabilities for complex workflows. For a deeper comparison of the tools available, you can read our analysis of Claude vs ChatGPT for technical tasks. And if you want to understand how to structure the first real-world project for Claude Code's autonomous mode, our step-by-step project structuring guide walks through a complete example.
Proven Strategies for Implementing Autonomous Healing
Progressive escalation, feedback loops, and iterative rollout turn Claude Code or GPT-4-orchestrated pipelines into learning systems that reduce on-call incidents by 60% within three months.
Building the initial skills is one thing; evolving them into a robust, production-grade system requires strategy. Here are advanced tactics to ensure your self-healing pipeline delivers long-term value.
Strategy 1: Implement Progressive Escalation
Not all failures are equal. Your system should have a tiered response strategy. The first line of defense is a simple retry (e.g., for a transient network error). The second is an automated remediation (e.g., schema repair). The final tier is a human alert.
Define clear escalation thresholds. For example: * Level 1: Retry the failed skill up to 3 times with exponential backoff. * Level 2: If retries fail, execute the designated remediation skill. * Level 3: If the remediation skill fails, or if the same failure pattern occurs 3 days in a row, send a high-priority alert to the engineering team with full context.
This ensures the system handles common, mundane issues silently while surfacing novel or persistent problems that might indicate a larger issue, like a fundamental change in a source API. This tiered approach is a hallmark of mature automation, moving beyond simple scripts to intelligent system management, a concept valuable for solopreneurs managing their own tech stacks.
Strategy 2: Build a Feedback Loop for Continuous Improvement
A self-healing pipeline should get smarter over time. Implement a feedback loop where the outcomes of remediation attempts are logged and reviewed.
This turns your pipeline from a static piece of code into a learning system. The operational data about the pipeline itself becomes fuel for its own enhancement.
Strategy 3: Start Small and Iterate
You don't need to convert your most critical, complex pipeline on day one. Start with a non-mission-critical data flow. Focus on implementing atomic skills for just two or three key steps, like ingestion and basic validation. Design one simple remediation, like a retry with a fallback file.
This approach lets you: * Test the Ralph Loop Skills Generator workflow and your collaboration with Claude Code in a low-risk environment. * Work out the practical kinks of skill definition and orchestration. * Demonstrate tangible value (e.g., "Pipeline X hasn't woken us up at night for two weeks") to build buy-in for broader adoption.
Once you have a proven pattern, you can apply it to more important pipelines, adding more sophisticated validation and remediation skills as needed. This iterative, value-driven approach is far more sustainable than a risky "big bang" rewrite. For a comprehensive look at integrating AI into your development hub, explore our Claude hub.
Got Questions About Self-Healing Pipelines? We've Got Answers
Four answers on development time ROI, handling novel failures, the biggest starter mistake, and why solopreneurs benefit most from Claude Code-orchestrated self-healing pipelines.
How much initial development time does this approach add?
It adds significant upfront time, often doubling the initial development effort compared to a basic, fragile script. You're not just writing the "happy path" logic; you're designing validation checks, failure detection, and repair procedures. However, this investment is recouped many times over in reduced operational burden. Within a few months, the time saved on manual troubleshooting, on-call incidents, and "data firefighting" will typically surpass the extra initial development time. Think of it as building a more durable machine that requires less maintenance.
Can this handle truly novel, unexpected failures?
No, and it's not meant to. A self-healing pipeline is designed to handle known failure modes—the common, repetitive breaks that consume most of your support time. It codifies your team's existing tribal knowledge into automated playbooks. A truly novel, unprecedented failure (e.g., a source system returning encrypted data instead of JSON) will likely bypass the automated checks and require human intervention. The system's job is to alert you clearly with all available context when this happens, so you can focus on solving new problems, not old ones.
What's the biggest mistake people make when starting?
The biggest mistake is trying to build a perfect, all-encompassing system from the start. They get bogged down designing for every hypothetical failure mode before they've handled the one that breaks every Tuesday at 3 AM. Start with the single most painful, frequent failure in your most annoying pipeline. Build one atomic skill to detect it and one to fix it. Get that working and delivering value. This concrete win provides motivation, uncovers the real patterns of working with Claude Code, and creates a template you can replicate and scale.
Is this only for large engineering teams?
Not at all. In fact, solopreneurs and small teams often benefit the most. They have the most to lose from being woken up by a broken pipeline and the least bandwidth for manual toil. Using Claude Code with the atomic skills approach allows a single developer to build and maintain a resilient data infrastructure that would normally require a dedicated operations person. The key is starting small and focusing on automating the failures that cause the most personal disruption.
Ready to stop babysitting your data pipelines?
The Ralph Loop Skills Generator structures validation and remediation skills that Claude Code, Cursor, or GitHub Copilot can execute autonomously with zero manual intervention.
Ralph Loop Skills Generator helps you turn the complex problem of pipeline resilience into a series of solvable, atomic tasks. Define clear validation and remediation skills, and let Claude Code orchestrate the workflow, iterating until everything passes. Start building pipelines that fix themselves. Generate Your First Skill<!-- sister-projects-start -->
Other Doved Studio projects
Related tools from the same studio you might find useful:
- Glean: Turn scrolling time into a daily action plan. Capture, process, execute.
- Popout: Create your portfolio in minutes with a single shareable page.
- Larpable: Spot fake founders, guru grifts, and performance entrepreneurship.
- Doved Studio: Studio indie derrière cette app et une dizaine d'autres outils.
ralph
Building tools for better AI outputs. Ralphable helps you generate structured skills that make Claude iterate until every task passes.