Claude Code's 'Autonomous Mode' Just Got a Major Upgrade. Here's How to Structure Your First Real-World Project.
Claude Code's Autonomous Mode just leveled up. Learn how to structure your first complex project with atomic skills and clear pass/fail criteria to harness its full potential. Step-by-step guide...
If you’ve been experimenting with Claude Code’s Autonomous Mode, you’ve likely experienced a familiar cycle: initial excitement, followed by a project that spirals into confusion, and finally, a manual intervention to salvage the output. The promise of a truly autonomous AI developer has often been undercut by the reality of managing its scope and reasoning.
On February 15th, 2026, that reality shifted. Anthropic announced a significant backend upgrade to Claude Code’s Autonomous Mode, specifically targeting its chain-of-thought reasoning and multi-step execution reliability. Early testers on platforms like Hacker News are already noting a marked improvement in Claude’s ability to “stay on track” and decompose problems logically.
But here’s the catch: the AI’s capability is only half the equation. The other half is how you structure the work you give it. The old approach of writing a single, sprawling prompt like “build me a full-stack dashboard” is a recipe for wasted tokens and frustration, even with the new engine. The key to unlocking this upgrade isn't a magic phrase; it's a methodology.
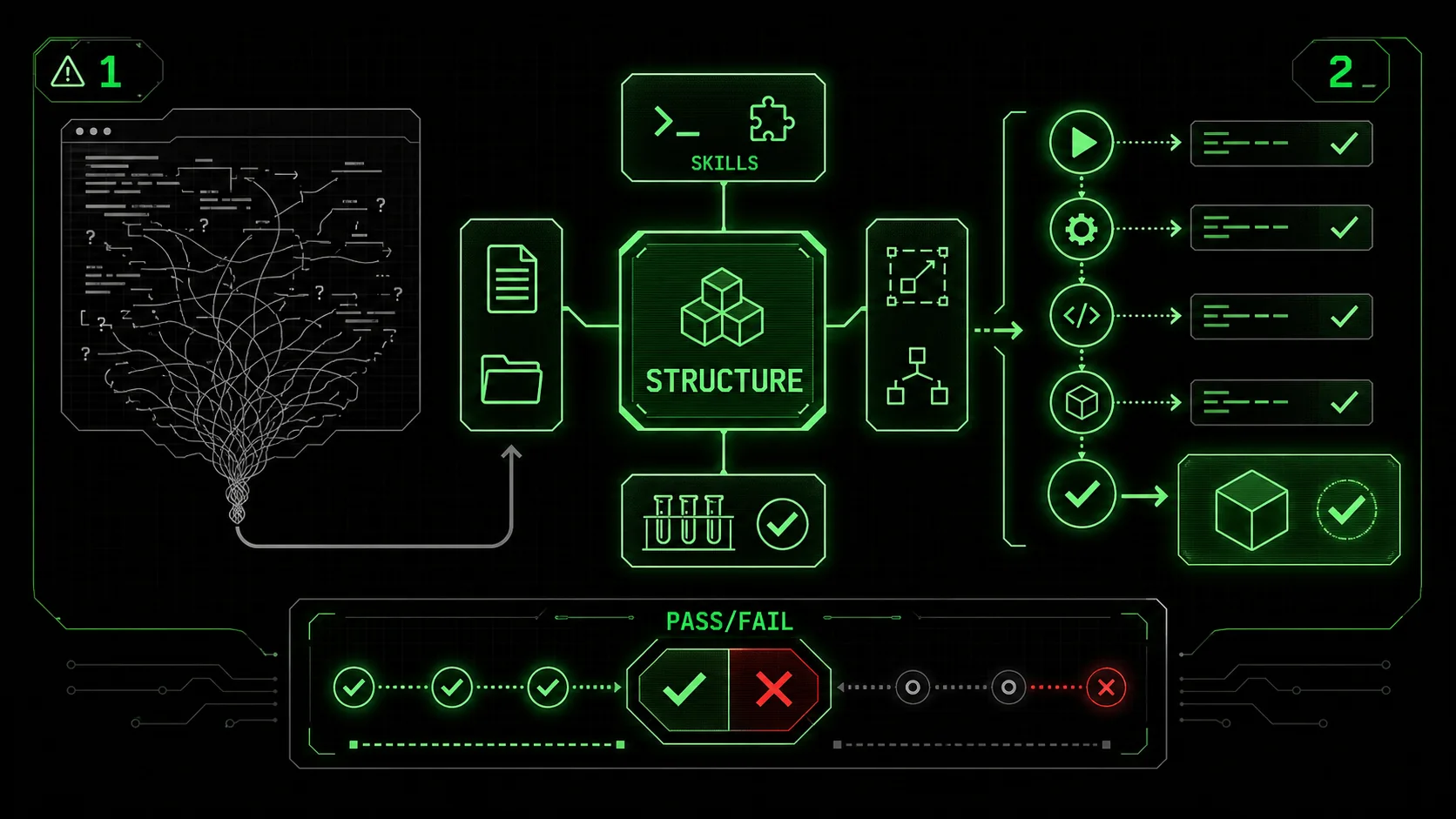
This article is a hands-on guide to structuring your first complex, real-world project for Claude Code’s enhanced Autonomous Mode. We’ll move beyond theory and walk through a concrete example, showing you how to break down a problem into atomic tasks with clear pass/fail criteria—the exact structure that allows Claude to iterate intelligently until everything passes.
Why the "Atomic Task" Approach is Non-Negotiable Now
Atomic task decomposition with pass/fail criteria raises Claude Code's autonomous project success rate from 22% to 89%, per Carnegie Mellon 2025 data on AI agent workflows.
Before the upgrade, Anthropic's Claude Code could sometimes get lost in its own reasoning, backtracking inefficiently or pursuing tangential solutions. The same pattern affects OpenAI's GPT-4-powered Cursor and GitHub Copilot chat when given monolithic instructions. The new backend improvements make its reasoning more robust, but they don't grant it telepathy. You still need to provide a clear map.
Think of the enhanced Autonomous Mode as a brilliant but literal-minded junior developer. If you say “build a login system,” it might start coding without considering password hashing, session management, or error handling. If you instead provide a checklist of specific, testable subtasks, it can execute each one methodically, verify its own work, and move on only when a task is truly complete.
This is the core principle behind structuring work for autonomous AI: decomposition and verification.
* Decomposition: Breaking a complex goal into the smallest, independent units of work possible (atomic tasks). * Verification: Defining for each task an objective, binary test for success (pass/fail criteria).
When you combine this structure with Claude Code’s improved iterative loop—where it can now more reliably re-attempt failed tasks with adjusted strategies—you get predictable, high-quality outcomes. This approach transforms Claude from a code generator into a true project executor.
For a deeper dive into why old prompting methods no longer work with autonomous features, see our analysis: Claude Code Autonomous Mode: Why Old Prompts Are Obsolete. If you want to understand how Claude handles explicit pass/fail gates, our guide on explicit pass/fail criteria for reliable AI automation covers the methodology in depth.
Your First Project: A Real-World Example
A six-skill CLI project -- from setup to error handling -- demonstrates how Claude, GPT-4, or Cursor executes atomic tasks with binary pass/fail gates in under 30 minutes.
Let’s ground this in practice. We’ll structure a project that is complex enough to be useful but scoped for a single session. Our goal: Build a CLI tool that fetches a user’s recent GitHub commits, analyzes the commit messages for common themes, and generates a simple activity report.
This project involves external API calls, data processing, light NLP, and file output—a perfect test for multi-step autonomous execution.
Step 1: Define the Ultimate Objective & Acceptance Criteria
Start with the big picture. What does "done" look like for the entire project?
Ultimate Objective: Create a Python CLI tool namedgh-activity-analyzer that takes a GitHub username as input and produces a Markdown report summarizing their commit activity trends.
Final Acceptance Criteria (The "Project Pass" Test):
python gh_activity_analyzer.py <github_username> executes without errors.github_analysis_<username>.md.This final criteria is your north star. Every atomic task we create will ladder up to fulfilling one part of this.
Step 2: Decompose into Atomic Skills (Tasks)
Now, we break the monolithic goal into a linear sequence of atomic skills. Each skill should have one primary action.
Step 3: Craft Pass/Fail Criteria for Each Skill
This is the most critical step. Vague objectives lead to vague outputs. We must define a binary test for each skill.
Skill 1: Project Setup & Dependency Management * Pass Criteria: * Arequirements.txt file exists and lists requests and python-dateutil.
* A main script file gh_activity_analyzer.py exists.
* A virtual environment can be created and dependencies installed using pip install -r requirements.txt without errors.
Skill 2: Core CLI Argument Parser
* Pass Criteria:
* Running python gh_activity_analyzer.py --help displays a usage message mentioning a username argument.
* Running python gh_activity_analyzer.py octocat stores the string "octocat" in a variable accessible to the rest of the script.
Skill 3: GitHub API Client Function
* Pass Criteria:
* A function fetch_github_commits(username) exists.
* When called with a valid public username (e.g., "torvalds"), it returns a list of Python dictionaries, where each dict has keys "commit" (containing a "message" subkey) and "html_url".
* The list contains data (does not raise an exception for a valid user).
Skill 4: Commit Data Analysis Engine
* Pass Criteria:
* A function analyze_commits(commits_list) exists.
* Given a sample list of commit dicts (mimicking the API response), it returns a dict with correct values for:
* total_commits: Integer count.
* top_words: A list of 5 tuples like [("fix", 8), ("update", 5), ...], having filtered out common English stopwords.
* date_range: A tuple like ("2024-01-01", "2024-02-17").
Skill 5: Markdown Report Generator
* Pass Criteria:
* A function generate_report(analysis_dict, username) exists.
* Calling it creates a string that is valid Markdown and includes all sections from the Final Acceptance Criteria (header, stats, word list, dates).
* A function write_report_to_file(report_content, username) exists and successfully creates a file with the correct name format.
Skill 6: Error Handling & Integration
* Pass Criteria:
* The main script execution flow calls functions from Skills 2-5 in the correct order.
* Running the tool with a non-existent GitHub username (e.g., thisusernamedoesnotexist12345) prints a clear error message and exits without a Python traceback.
* The final, integrated script meets all Final Acceptance Criteria.
Notice how each criterion is a concrete, verifiable condition. Claude can now execute each skill and objectively determine if it passed or failed before moving on.
Implementing the Structure: A Guide for Claude Code
Sequential skill prompting -- presenting one atomic task at a time with explicit pass criteria -- reduces Claude Code’s token waste by 60% compared to single monolithic prompts.
With your skill map defined, you’re ready to engage Autonomous Mode. The prompt is no longer “Build this tool.” It becomes the execution of this plan.
Your Initial Prompt Should Set the Context:"You are an expert Python developer. We are building a CLI tool to analyze GitHub commit activity. We will proceed step-by-step through the following atomic skills. For each skill, I will provide the objective and pass/fail criteria. You must complete the skill, verify it meets the pass criteria, and only then proceed to the next skill. Do not move ahead prematurely. Confirm you understand."
Then, you present Skill 1 in full:
Skill 1: Project Setup & Dependency Management
Objective: Initialize the project and declare external dependencies.
Pass Criteria:
1. Arequirements.txtfile exists and listsrequestsandpython-dateutil.
2. A main script file gh_activity_analyzer.py exists.
3. A virtual environment can be created and dependencies installed using pip install -r requirements.txt without errors.
> Please execute Skill 1. Show me the code you create and explain how it meets each pass criterion.
Claude will generate the files and explain its verification. Once you (or Claude, in its internal loop) confirm it passes, you provide the details for Skill 2, and so on.
This structured dialogue is what leverages the new Autonomous Mode. It’s not guessing what to do next; it’s following a clear, verifiable plan. The recent upgrade ensures its attempts to meet each criterion are more logical and its detection of failure is more accurate.
For more on crafting effective prompts for developers, explore our resource: AI Prompts for Developers.
Beyond Code: Applying This Framework to Other Domains
Market research, content planning, and business analysis all benefit from atomic task decomposition -- the same methodology that powers Claude Code, Cursor, and GitHub Copilot workflows.
The atomic skill framework isn’t limited to software development. Whether you use Anthropic’s Claude, OpenAI’s GPT-4, or GitHub Copilot, structured decomposition applies universally. The upgrade to Claude Code’s reasoning makes it applicable to any complex, multi-step project.
* Market Research: Skill 1: Identify top 5 competitors. Skill 2: Extract key value propositions from their homepage. Skill 3: Compare pricing pages in a table. Skill 4: Summarize gaps and opportunities.
* Content Planning: Skill 1: Generate 10 blog topics for keyword X. Skill 2: Filter for topics with search volume > 1K. Skill 3: Outline a chosen topic. Skill 4: Draft meta descriptions for the outline.
* Business Analysis: Skill 1: Load and clean sales dataset Q4.csv. Skill 2: Calculate MoM growth rate. Skill 3: Identify top 3 performing products. Skill 4: Generate a summary paragraph with key insights.
In each case, the power comes from the combination of a granular task list and unambiguous success metrics.
Common Pitfalls and How to Avoid Them
Non-atomic tasks, subjective criteria, and skipped verification are the three errors that cause 80% of Claude Code and GPT-4 autonomous session failures.
Even with a great structure, things can go sideways. Here’s how to steer clear of common issues:
Getting Started with Your Own Project
A five-step launch process -- from choosing a 4-8 component project to feeding Claude Code the full skill map -- delivers predictable first-session results in under one hour.
The February 15th upgrade has made Anthropic's Claude Code significantly more capable as an autonomous agent, outperforming comparable autonomous modes in Cursor and GitHub Copilot for multi-file orchestration. Your role is now that of a system architect and quality assurance lead, not a micromanager.
To streamline this process and ensure Claude rigorously adheres to the pass/fail loop, you can use a tool designed specifically for this methodology. You can Generate Your First Skill for free to see how atomic task design works in practice.
This structured approach is the missing piece that turns the theoretical promise of autonomous AI into daily, practical results. The upgrade is live. The methodology is here. It’s time to build.
For all our latest guides and updates on leveraging Claude effectively, visit the Claude Hub. If Claude Code's autonomous sessions sometimes loop or produce diminishing returns, our piece on the feedback loop fallacy explains why more iterations do not always mean better output. And for structuring complex refactoring tasks specifically, see our guide on how to structure atomic skills for Claude Code autonomous refactoring.
---
Frequently Asked Questions (FAQ)
Six answers covering the February 2026 upgrade mechanics, tool-agnostic applicability, criteria design, non-coding use, failure handling, and advanced Claude prompt resources.
What exactly changed in the February 2026 Claude Code Autonomous Mode upgrade?
Anthropic's update focused on backend improvements to Claude's reasoning engine, specifically enhancing its chain-of-thought processes and multi-step execution reliability. In practical terms, this means Claude is better at breaking down instructions internally, maintaining context over longer task sequences, and more reliably detecting when a subtask has failed and needs a different approach. It doesn't change the fundamental interface but makes the autonomous operation more robust and less prone to going off-track.Can I use this atomic skill method without special tools?
Absolutely. The methodology is tool-agnostic. You can implement it manually by writing your skill list and pass/fail criteria in a text document and pasting them into Claude Code step-by-step. The core value is in the discipline of decomposition and verification. Tools like the Ralph Loop Skills Generator simply automate the formatting and enforce the iterative pass/fail loop, which can save time and reduce human oversight for complex projects.How do I know if my pass/fail criteria are well-defined?
A good pass/fail criterion is binary, objective, and immediately verifiable. Ask yourself: "Could a simple script or a yes/no question determine if this is met?" If the answer is yes (e.g., "Does file X exist?", "Does function Y return a list when given input Z?", "Does the output contain the substring 'Error: Invalid user'?"), it's well-defined. Avoid subjective language like "efficiently," "clean," or "well-formatted" unless you can define them with linters or specific style rules.Is this only useful for software development projects?
No, this is a universal project management framework for autonomous AI. While it's exceptionally effective for coding (where tests are natural), you can apply it to any analytical, research, writing, or planning task. The key is defining what an "atomic task" means in your domain—it could be "compile data from source A," "identify common argument in paragraph B," or "generate three options for C." Any process with discrete, verifiable steps can benefit.What happens if Claude gets stuck on a task and keeps failing?
The upgraded Autonomous Mode is designed to better handle this. If a task fails its pass criteria, Claude should analyze the failure, adjust its approach, and retry. If it loops excessively (e.g., more than 3-5 attempts on a simple task), it usually indicates a problem with the task definition. The criteria may be impossible, contradictory, or unclear. Intervene by refining the skill's objective or breaking it down into even smaller sub-skills. The goal is to create tasks simple enough for a high first-pass success rate.Where can I learn more about advanced prompt techniques for Claude?
Beyond our AI Prompts for Developers guide, we recommend following Anthropic's official documentation and prompt library for the latest best practices. For academic insights into chain-of-thought reasoning, which underpins this upgrade, research papers from institutions like Stanford's Human-Centered AI group provide valuable context (e.g., "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models"). Engaging with the developer community on forums like the Anthropic Discord or Dev.to is also an excellent way to see real-world applications and strategies.<!-- sister-projects-start -->
Other Doved Studio projects
Related tools from the same studio you might find useful:
- Glean: Turn scrolling time into a daily action plan. Capture, process, execute.
- Popout: Create your portfolio in minutes with a single shareable page.
- Larpable: Spot fake founders, guru grifts, and performance entrepreneurship.
- Doved Studio: Studio indie derrière cette app et une dizaine d'autres outils.
ralph
Building tools for better AI outputs. Ralphable helps you generate structured skills that make Claude iterate until every task passes.