The 'AI Agent Fatigue' Problem: Why Your Claude Code Projects Stall and How Atomic Skills Fix It
Is your Claude Code agent getting stuck? Discover the 'AI Agent Fatigue' problem and how breaking projects into atomic skills with clear criteria ensures your AI assistant finishes the job.
It’s February 2026, and a familiar frustration is echoing across developer forums and Slack channels. You’ve given Claude Code a complex task—refactoring a legacy module, building a full-stack feature, or automating a multi-step data pipeline. The initial output is promising. But then, it happens. The agent gets stuck in a loop, revising the same code with minor tweaks. It produces a solution that’s 90% correct but fails on a critical edge case. It seems to "forget" the original requirements, veering off on a tangent. The project stalls, your momentum is lost, and you’re left manually debugging the AI’s work, wondering if it saved you any time at all.
Welcome to AI Agent Fatigue.
This isn't a failure of the AI's raw capability. Claude Code, especially with its enhanced agentic features, is more powerful than ever. The problem lies in the orchestration of that power for complex, multi-step work. As the industry trend shifts from simple code snippets to orchestrating entire projects, the old approach of handing off a monolithic prompt is breaking down. The agent, lacking a clear map and checkpoints, gets lost in the complexity.
This article diagnoses the root causes of AI Agent Fatigue and introduces a systematic solution: the methodology of atomic skills with pass/fail criteria. By breaking down any complex problem into a sequence of verifiable, completable tasks, you can transform Claude Code from a brilliant but erratic assistant into a reliable, deterministic workflow engine that iterates until everything passes.
What is AI Agent Fatigue? Symptoms and Diagnosis
AI Agent Fatigue is the pattern of diminishing returns that occurs when Claude, GPT-4, or any agentic coding assistant tackles a problem too complex for a single unstructured prompt.
AI Agent Fatigue describes the diminishing returns and project stalls that occur when an AI coding assistant is tasked with a problem too complex for its context window and operational paradigm. It’s not that the AI stops working; it’s that its work ceases to be productive.
Let’s look at the common symptoms:
A recent thread on a popular developer forum titled "Claude Code Spinning Its Wheels on API Refactor" perfectly captures the fatigue. The developer’s goal was straightforward: update a set of API endpoints to a new authentication standard. Yet, the agent cycled for over 20 turns, alternately breaking the authentication, then the request parsing, then the response format, never achieving a fully passing state for all endpoints simultaneously. The developer concluded, "It's like watching a very smart intern get hopelessly lost in their own code."
The root cause is a lack of structure. We are asking an agent to navigate a multi-room maze without a map, expecting it to both chart the course and walk it in one go. This pattern is closely related to what we call context drift -- the gradual loss of focus across long AI sessions.
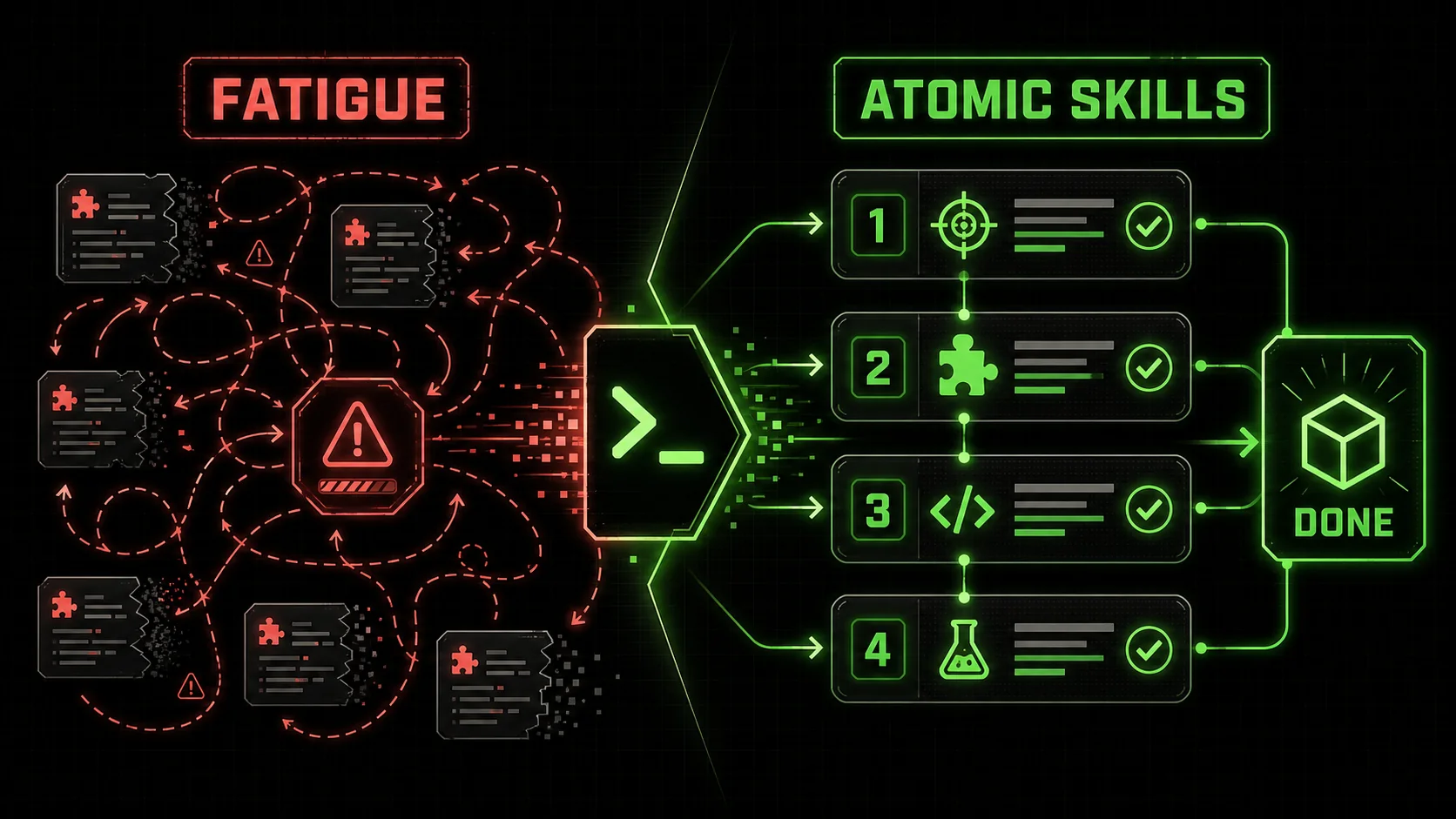
The Atomic Skills Antidote: From Monolithic Prompt to Managed Workflow
Atomic skills break one large AI task into small, verifiable steps with explicit pass/fail criteria so the agent completes each piece before moving on.
The solution to Agent Fatigue is not a more powerful model or a cleverer one-shot prompt. It’s a change in process. Instead of presenting the AI with a monolithic problem, we break it down into a sequence of atomic skills.
An atomic skill is a single, well-defined task with three critical components:
validate_user_input(data) that checks for null values and type conformity.")true for valid {name: 'Alice', age: 30} and false for {name: null, age: 'thirty'}. It includes unit tests for these cases.")This methodology transforms the human's role from a micromanager debugging each line to a systems architect and quality assurance lead. You define the workflow and the quality gates; Claude Code executes each step and proves it has met the criteria before moving on.
How Atomic Skills Solve the Fatigue Problem
Eliminates Infinite Loops: Each skill has a definitive end state (Pass). The agent iterates on that skill only* until it passes. It cannot wander into refactoring unrelated code or re-architecting the solution prematurely. Prevents "Almost There" Output: Pass criteria force consideration of integration, edge cases, and non-functional requirements at the task level*. A module isn't "done" until its tests pass. * Arrests Context Drift: The scope of each conversation turn is tightly bound to a single atomic skill. The objective and criteria are re-stated each time, keeping the agent focused. * Creates Progressive Clarity: A passed skill is a verified building block. The project advances on a foundation of known-good components, making the overall state clear and complexity manageable. * Streamlines the Handoff: The final deliverable is a collection of skills that have all individually passed their criteria. The integration risk is vastly lower, and the human can review with confidence.Implementing Atomic Skills: A Practical Guide with Claude Code
You implement atomic skills by decomposing a project into a skill chain, writing structured prompts with pass/fail gates, and verifying each output before feeding it to the next step.
Let’s move from theory to practice. How do you actually implement this with Claude Code?
Step 1: Decompose Your Project into a Skill Chain
Start by thinking in terms of outputs and dependencies. For a task like "Add user profile editing to the React frontend," a monolithic prompt is a recipe for fatigue. Instead, break it down:
ProfileForm.jsx with a form for name and email.ProfileForm.jsx for email format and non-empty name.This chain is linear, but skills can also be parallel or have conditional branches (e.g., "If Skill 1 finds no PATCH endpoint, then execute Skill 1a: Create the endpoint"). For a deeper look at connecting skills in sequence, see our guide to task chaining with atomic skills.
Step 2: Craft the Skill Prompt for Claude
For each skill, you provide Claude with a structured prompt. The Ralph Loop Skills Generator formalizes this, but the structure is simple:
Skill Objective: [The single task]
Input Context: [Relevant code, data, or decisions from previous skills]
Pass Criteria: [A bulleted list of conditions that must be true]
Fail Criteria/Boundaries: [What not to do]
Instructions: Execute this skill. Work iteratively. Output your final solution only when all Pass Criteria are satisfied. If you hit a blocker, explain it clearly.Skill Objective: Connect the ProfileForm component to the User API PATCH endpoint to update user data.
Input Context: 1) API Endpoint: PATCH /api/users/me, requires Auth header, expects {name, email}. 2) ProfileForm component with state for formData and validation.
Pass Criteria:
- On form submission, an HTTP PATCH request is sent to
/api/users/me.
- The request includes the
Authorization: Bearer <token> header (use a placeholder).
- The request body is the
formData object.
- On a successful response (2xx), a green "Profile Updated!" message is displayed.
- On an error response (4xx/5xx), the error message from the server is displayed in red.
Fail Criteria/Boundaries: Do not implement token retrieval logic. Do not modify the validation logic from Skill 3.
Instructions: Implement this integration in the ProfileForm component. Show the final, updated component code.Step 3: Execute and Verify Iteratively
You present Skill 1 to Claude Code. It works until it meets the pass criteria and presents the output. You, as the human, can quickly verify the summary looks correct. You then take the output of Skill 1 and paste it as the "Input Context" for Skill 2.
This creates a verified context chain. Each step builds on a confirmed foundation. Claude is not trying to hold the entire project in its context; it's focusing on one verified piece of input to produce one verifiable output.
If a skill fails—for example, the tests in Skill 5 don't pass—you don't revert the whole project. You tell Claude to iterate on that specific skill, using the same prompt and criteria. The isolation makes debugging the AI's work trivial.
Beyond Code: Applying Atomic Skills to Research, Planning, and Analysis
Atomic skills work for market research, project planning, and data analysis tasks just as effectively as they do for coding workflows with Claude Code or GitHub Copilot.
While coding is a prime example, the atomic skills methodology is a general-purpose framework for complex AI-assisted work. Agent Fatigue plagues these areas too.
* Market Research: Instead of "Research the competitive landscape for no-code analytics tools," create skills for: 1) Identify top 5 competitors, 2) Extract pricing pages into a table, 3) List key features of each, 4) Summarize differentiation points. Each skill has pass criteria for source quality, data format, and completeness. * Project Planning: For "Plan the Q3 product launch," use skills like: 1) Output a timeline of key milestones from today to launch, 2) List required assets (website copy, datasheets, demo videos), 3) Identify dependencies between engineering and marketing tasks. Pass criteria ensure dates are coherent and no major phase is missing. * Data Analysis: For "Analyze this sales CSV," break it into: 1) Clean the data (remove nulls, standardize formats), 2) Calculate monthly revenue trends, 3) Identify top 5 customers by volume, 4) Create a summary paragraph of insights. Each step's output is a specific, verifiable artifact.
In each case, you move from an open-ended, fatigue-prone dialogue to a structured workflow where progress is measurable and the AI's role is precisely defined.
The Future of Agentic Work: Skills as the Fundamental Unit
Anthropic, OpenAI, and the broader AI industry are converging on structured, multi-turn collaboration as the standard for agentic coding assistants in 2026.
The industry discussion in early 2026 is converging on this need for structure. Anthropic's focus on enhancing Claude's "agentic" capabilities underscores that the future is not about one-off generation, but about reliable, multi-turn collaboration. The atomic skill is emerging as the fundamental unit of this collaboration. This pattern applies equally whether you use Claude Code, Cursor, or GitHub Copilot -- the key is structuring your prompts around verifiable atomic units of work.
By adopting this methodology, you're not just solving today's Agent Fatigue; you're building a reusable library of verified skills. A "user authentication skill chain" or a "data visualization skill chain" can be adapted and reused across projects, compounding your productivity gains.
The tools are evolving to support this. While you can implement this manually with careful prompting, purpose-built systems like the Ralph Loop Skills Generator are designed to systematize the process—helping you decompose problems, generate clear pass/fail criteria, and manage the execution flow, turning Claude Code into a truly reliable project partner.
Ready to eliminate Agent Fatigue from your next project? Start by breaking down your next complex task into three atomic skills with clear pass/fail criteria. You can also Generate Your First Skill with our structured tool to experience the difference immediately.
FAQ: AI Agent Fatigue and Atomic Skills
What's the difference between "chunking" a prompt and creating atomic skills?
Chunking is about managing token limits by breaking a large input into pieces. Atomic skills are about managing task complexity and verification. A skill includes a clear objective and, crucially, pass/fail criteria that define what a correct completion looks like. It's a unit of work with a quality gate, not just a piece of information.
Can't I just write a better, more detailed initial prompt to avoid fatigue?
A more detailed prompt can help, but it has limits. It increases the initial cognitive load on both you and the AI, and it still presents a monolithic problem. When the agent encounters an unforeseen issue 15 steps into the task, it lacks a structured way to recover. Atomic skills provide a built-in recovery mechanism: iteration on the current skill until it passes.
Is this methodology only useful for very large projects?
Not at all. It's highly effective for any task with more than 2-3 logical steps or any degree of uncertainty. Even a medium-complexity task like "fix this bug that occurs when the API returns a 204 No Content response" can be broken into: 1) Reproduce the bug locally, 2) Identify the exact line causing the error, 3) Propose and implement a fix, 4) Write a test for the 204 case. This prevents the agent from jumping to a fix without proper diagnosis.
How do I know if my pass/fail criteria are well-defined?
Good criteria are specific, objective, and testable. Avoid subjective language like "clean code" or "efficient." Instead, use objective checks: "Function includes JSDoc comments," "Algorithm completes in under O(n log n)," "All console errors from the original report are resolved." If you can imagine writing a simple script to verify the criteria, they are well-defined. For more on crafting effective prompts, see our guide on how to write prompts for Claude.
Does this mean I have to micromanage every tiny step?
Quite the opposite. This moves you away from micromanagement. Instead of reviewing every line of code in a 300-line change, you are reviewing the result of a 30-line atomic skill against 3-4 clear criteria. You define the "what" and the "quality standard"; the AI handles the "how." It's a higher-level, more efficient form of oversight.
Where can I learn more about advanced AI-assisted development workflows?
The field is rapidly evolving. We recommend following Anthropic's technical publications for insights into Claude's capabilities. For practical community discussions and shared techniques, developer forums and subreddits dedicated to AI coding are invaluable. You can also explore our broader collection of strategies in our article on AI prompts for developers. For the latest on integrating these methods, check our Claude Hub. If you want to understand how Claude Code's feedback loops can compound this problem, read about the feedback loop fallacy. And for a head-to-head comparison of how Claude and ChatGPT handle agentic workflows, see our Claude vs ChatGPT breakdown.
<!-- sister-projects-start -->
Other Doved Studio projects
Related tools from the same studio you might find useful:
- Glean: Turn scrolling time into a daily action plan. Capture, process, execute.
- Popout: Create your portfolio in minutes with a single shareable page.
- Larpable: Spot fake founders, guru grifts, and performance entrepreneurship.
- Doved Studio: Studio indie derrière cette app et une dizaine d'autres outils.
ralph
Building tools for better AI outputs. Ralphable helps you generate structured skills that make Claude iterate until every task passes.