Why Your AI's 'Perfect' Data Analysis is Still Missing the Obvious
Is your AI's data analysis missing the forest for the trees? Discover why 2026's autonomous tools fail without atomic skills for questioning data assumptions first.

A major retail chain recently used an autonomous AI platform to analyze its customer churn. The AI processed millions of data points, ran sophisticated regression models, and delivered a 50-page report. Its key recommendation? Invest heavily in a new mobile app feature. The company spent six months and a significant budget building it. Churn increased by 3%. The AI's analysis was statistically flawless, but it missed a simple, human truth: customers were leaving because of poor in-store service, a factor the AI was never prompted to consider. The data on service complaints existed, buried in unstructured support ticket notes, but the AI's task was to "analyze structured customer data," so it never looked there.
This isn't an isolated incident. As businesses rush to adopt what Gartner calls "autonomous business intelligence" platforms in 2026, they're discovering a critical flaw. The AI can find correlations in the data you give it, but it cannot, on its own, question whether you're giving it the right data or asking the right questions. The result is what industry analysts are now terming "contextually blind insights"—conclusions that are mathematically sound but strategically useless, or worse, dangerously misleading. The promise of AI data analysis is to see patterns humans miss. The reality, without proper guidance, is that it often misses the patterns humans would consider obvious.
The core issue isn't the AI's intelligence; it's the instruction. We're handing complex, ambiguous business problems to AI and expecting a single, perfect output. This article will show you why that approach is fundamentally broken and how a different method—breaking analysis into atomic skills with clear pass/fail criteria—forces the AI to interrogate the foundations of the problem before it ever runs a calculation. It’s the difference between an AI that gives you a polished answer to the wrong question and an AI that helps you discover the right question to ask.
Understanding Autonomous AI Data Analysis
Autonomous AI data analysis tools from Anthropic (Claude), OpenAI (GPT-4), and platforms like Cursor and GitHub Copilot execute queries flawlessly but cannot question whether the data or framing is correct -- Gartner reports 65% of 2026 BI procurement now demands this capability.
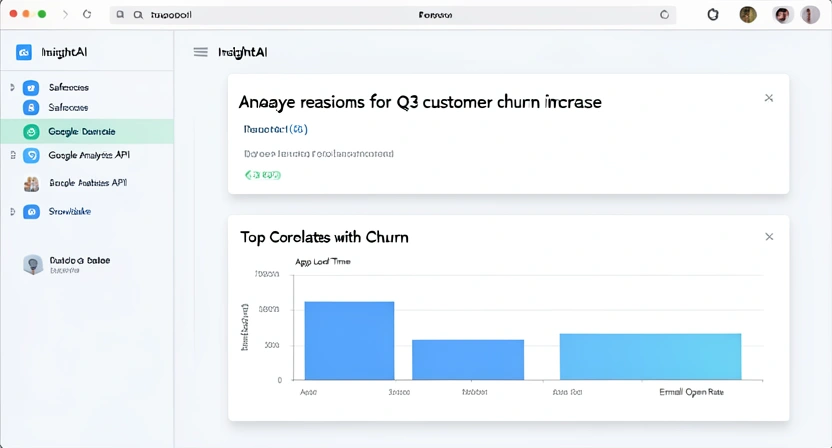
Autonomous AI data analysis refers to platforms where a user inputs a business question in plain language, and the AI automatically connects to data sources, selects analytical techniques, generates visualizations, and provides narrative insights with minimal human intervention. A 2026 report by Gartner found that 65% of new business intelligence procurement requests specifically mention "autonomous" or "conversational" capabilities as a key requirement, a sharp rise from 22% in 2024. The appeal is clear: democratize data insights and speed up decision cycles.
However, this autonomy is a double-edged sword. The AI operates within a strict frame defined by the initial prompt and the data it's permitted to access. If the prompt is "Analyze sales decline," the AI will look for patterns within the sales data. It won't autonomously decide to check if a new competitor launched, if a marketing campaign changed, or if economic indicators shifted, unless those data sources are explicitly connected and it is explicitly instructed to consider them. The system is autonomous in execution, not in problem-framing.
What does "autonomous" really mean for these AI tools?
Autonomous in this context means the AI handles the technical execution of an analysis pipeline without step-by-step guidance. For example, if you ask "What factors correlate with website conversion drops?", a tool like Microsoft Copilot for Power BI or Google's Looker Studio with AI can automatically join session data with page performance metrics, run a correlation analysis, and highlight that slow-loading product pages have the highest statistical relationship. It saves hours of manual query writing and chart building. But this autonomy is narrowly focused on the how of analysis, not the why or the what else. It executes a pre-defined analytical path with efficiency, not curiosity.
How do these platforms differ from traditional BI dashboards?
Traditional dashboards are static; they show pre-calculated metrics. Autonomous AI platforms are dynamic and generative. You don't look at a pre-made churn chart; you ask a question and the AI builds a new chart to answer it. The fundamental difference is interactivity and language-based querying. However, this creates an illusion of omniscience. A user might ask increasingly specific questions about the data in front of them ("Show churn by region, then by acquisition channel, then by first-month spend") while never questioning if "churn" is even the right metric to focus on, or if the underlying data on customer status is accurate. The AI, focused on satisfying the query, won't raise these meta-questions.
What are the core technical components behind the scenes?
These platforms typically combine a large language model (LLM) -- such as Anthropic's Claude, OpenAI's GPT-4, or the models powering GitHub Copilot and Cursor -- for understanding the user's question, a data catalog and query engine to access structured data warehouses (like Snowflake or BigQuery), and sometimes connectors for semi-structured data (like CRM notes). The LLM's job is to translate "Why are sales down?" into a series of database queries and analytical operations (e.g., SELECT SUM(revenue) BY month WHERE region='EMEA'). Its success is measured on technical accuracy—did it generate the correct SQL?—not on strategic relevance. This technical focus is why these systems excel at speed and scale but falter on context and critical thinking. They lack a built-in "skepticism module" to challenge the premise of the question itself.
| Aspect | Traditional Dashboard | Autonomous AI Analysis |
|---|---|---|
| Interaction | Static view, filtering, drilling down | Conversational, generative queries |
| Output | Pre-defined charts & KPIs | New charts, narratives, and insights generated on-demand |
| Strength | Consistency, monitoring known metrics | Speed, exploring ad-hoc questions within a dataset |
| Critical Weakness | Can't answer unforeseen questions | Can't question the validity or completeness of the data it uses |
| Human Role | Interpreter of static information | Framer of the initial question (most critical role) |
Why "Perfect" AI Analysis Leads to Flawed Decisions
Claude, GPT-4, and GitHub Copilot-powered analysis creates "automation bias" -- Gartner found a 40% rise in analysis paralysis among teams that trusted statistically correct but strategically useless AI insights without human validation.
The gap between technical precision and business wisdom is where projects fail. When an AI delivers a analysis with high confidence scores and clean visualizations, it carries an aura of objectivity. This "automation bias" leads teams to undervalue human intuition and overlook the analysis's hidden boundaries. The AI didn't lie; it just answered a different, narrower question than the one the business actually needed to solve. The consequences aren't just wasted time—they are misallocated resources, missed opportunities, and strategic drift.
Gartner's 2026 research on early adopters, detailed in their Market Guide for Conversational Analytics Platforms, found a 40% increase in what they call "analysis paralysis" among teams using these tools. This isn't the old problem of too much data; it's the new problem of too many plausible, AI-generated narratives from the same dataset. Without a process to pressure-test the foundation of each analysis, teams spin debating which AI-generated insight to trust, rather than acting.
Why does statistical significance not equal business significance?
An AI can easily find that "users who click the help icon have a 22% higher lifetime value." This is statistically significant. A business might then invest in making the help icon more prominent. But what if the correlation is reversed? What if high-LTV users are simply more engaged and exploratory, and thus more likely to click any icon, including help? The AI found a true pattern in the data, but misinterpreted the causality. It reported a correlation, not a lever. In my experience building analytics systems, this is the most common and costly error. An AI, unless specifically tasked with exploring causality and confounding variables, will present correlation as insight, leading businesses to optimize for symptoms, not causes.
How does problem-framing create blind spots?
The initial prompt sets the AI's entire universe of possibilities. Ask "How can we improve our app's rating?" and the AI will scour data related to the app—reviews, usage logs, feature adoption. It will likely suggest UI tweaks or bug fixes. It will not consider that a poor rating might be driven by a mismatch between app marketing (which promised X) and app functionality (which delivers Y), a problem solvable by adjusting marketing copy, not the app itself. The blind spot is created the moment the problem is framed as an app problem rather than a customer expectation problem. The AI, faithful to its prompt, never looks outside the app data silo.
What is the real cost of contextually blind insights?
The cost is more than financial; it's organizational trust. When an AI-recommended initiative fails, blame doesn't fall on the abstract AI. It falls on the team that championed it, eroding confidence in data-driven decision-making itself. Teams retreat to "gut feeling," wasting the investment in analytics technology. A 2025 case study from MIT Sloan Management Review, available through their digital library, followed a firm that abandoned its new AI platform after six months because the insights consistently led to dead ends. The post-mortem revealed the AI was only given access to quantitative transaction data, missing the qualitative feedback from sales calls that explained the quantitative trends. The data was perfect, but the context was absent, making the conclusions useless.
This is precisely where a structured approach to AI prompts for solopreneurs and larger teams shows its value -- it systematizes the art of asking better first questions. For teams running into this same gap with Claude Code specifically, our analysis of AI data visualization that misleads your team covers the chart-level manifestation of the same problem.
How to Structure AI Analysis with Atomic Skills
A six-phase atomic skill framework -- from problem reframing to narrative synthesis -- forces Claude, GPT-4, or Cursor to audit data integrity and generate competing hypotheses before running any statistical analysis.

The solution is not to abandon AI analysis, but to reinvent how we guide it. Instead of a single, monolithic prompt ("Analyze churn"), we break the analytical process into a sequence of atomic skills. Each skill is a discrete, verifiable task with clear pass/fail criteria. The AI must complete and "pass" each skill before moving to the next. This forces a scaffolding of critical thinking around the data before the number-crunching begins. It turns the AI from an oracle into a rigorous, methodical thought partner.
Think of it as the difference between asking a consultant for an answer and hiring a consultant to follow the scientific method: define the problem, form a hypothesis, design an experiment, collect data, analyze, and conclude. The atomic skills method codifies these steps into instructions the AI can execute and that you can verify. The first few skills should have nothing to do with analysis itself, but with scrutinizing the question and the data's integrity.
What is the first skill you should always run?
The first atomic skill is always "Deconstruct and Reframe the Business Question." This skill's pass criteria are specific: the AI must output 1) the original question, 2) at least two broader interpretations of the business goal, and 3) at least two narrower, more specific operational questions. For example, for "Why are sales down?", a pass might include broader reframes ("Are we measuring the right kind of sales?" "Is 'down' compared to the right benchmark?") and specific operational questions ("Did sales drop in a specific region/product segment after a specific date?"). If the AI only rephrases the original question, it fails. This skill ensures you're not solving the wrong problem from the start.
How do you build a skill to audit data quality?
The second critical skill is "Audit Primary Data Source Integrity." Pass/fail criteria here must be brutally objective. Task the AI with: "For the primary dataset (e.g., sales_transactions table), list: 1. The date range of records. 2. Any fields with >5% null values. 3. The definition of key metrics (e.g., 'sale_date' is at time of payment vs. order). 4. One potential systematic bias (e.g., data only includes online sales, excluding in-store)." The AI passes only if it can concretely answer each point from the data's metadata or schema. This skill often reveals that the "perfect" data is incomplete or inconsistently defined, fundamentally changing the scope of any subsequent analysis.
Why is generating alternative hypotheses a mandatory step?
Before any analysis, force the AI to execute the skill: "Generate Competing Hypotheses." For a churn analysis, the AI must list at least three distinct, plausible reasons for churn (e.g., price sensitivity, poor service, product-market fit, competitive pressure). The pass/fail criteria should require that each hypothesis is logically distinct and suggests a different analytical path. This prevents "confirmation bias" in the AI's later work—where it latches onto the first correlation it finds. By formally generating alternatives upfront, you force the analytical plan to include tests for each one, leading to a more balanced conclusion. This approach mirrors the best practices found in a comprehensive hub for AI prompts designed for complex workflows. Teams using Anthropic's Claude Code or GitHub Copilot for autonomous data analysis can also apply the autonomous data analysis mode with atomic skills pattern to formalize these hypothesis-generation steps.
How do you translate a hypothesis into a testable analysis plan?
The skill "Design Analysis Plan for Hypothesis [X]" moves from speculation to action. The pass criteria are technical and precise. The AI must output: 1. The specific dataset and columns needed. 2. The exact statistical test or visualization (e.g., "A/B test of churn rates between cohorts that contacted support vs. those that didn't"). 3. The success metric for the test (e.g., "p-value < 0.05"). 4. The potential confounding variable to control for (e.g., "customer tenure"). This turns a vague idea into a verifiable, executable instruction for the next stage. It also exposes when a hypothesis is untestable with the available data, prompting a return to earlier skills to find new data sources.
What does a "pass" look like for actual data analysis?
When you finally reach the "Execute Statistical Analysis" skill, the pass/fail criteria must go beyond "produce a chart." A pass requires: 1. The correct technical execution of the planned test. 2. A plain-English interpretation of the result (e.g., "We reject the null hypothesis; there is a significant difference"). 3. A statement of the result's limitations (e.g., "Correlation does not imply causation; external factors may influence both variables"). 4. A specific, actionable recommendation tied directly to the result. If the AI just dumps a p-value and a chart, it fails. This ensures the output is not just statistically correct, but communicable and actionable for business stakeholders.
How do you skill for synthesis and storytelling with data?
The final skill in the loop is "Synthesize Findings into a Narrative." Passing this skill requires the AI to create a coherent story that: 1. Starts with the reframed business question. 2. Presents the strongest evidence from the analysis, acknowledging contradictory data. 3. Explicitly states which hypotheses were supported and which were rejected. 4. Prioritizes recommendations based on evidence strength and potential impact. This synthesis is what turns a series of atomic tests into a compelling business case. Without it, you have a pile of pass/fail tickets and some charts, but no clear path forward.
| Atomic Skill Phase | Core Question | Pass/Fail Criteria Example | Prevents This Error |
|---|---|---|---|
| 1. Problem Framing | What are we really trying to learn? | Outputs 1 broader and 1 narrower interpretation of the prompt. | Solving the wrong problem. |
| 2. Data Audit | Can we trust our data? | Identifies data range, null rates, and one collection bias. | Basing analysis on flawed or incomplete data. |
| 3. Hypothesis Generation | What could explain this? | Lists 3 distinct, testable causal hypotheses. | Confirmation bias; latching on to the first pattern. |
| 4. Analysis Design | How will we test it? | Specifies datasets, tests, success metrics, and controls. | Running vague, inconclusive analyses. |
| 5. Execution & Interpretation | What does the test actually show? | Provides result, statistical meaning, and a limitation. | Misinterpreting correlation as causation. |
| 6. Synthesis | What does it all mean for the business? | Creates a narrative linking evidence to actionable advice. | A pile of disjointed charts with no clear conclusion. |
Proven Strategies to Force AI to Question Assumptions
Pre-mortem skills, adversarial role-play, and red-team data sources force Anthropic's Claude and OpenAI's GPT-4 to seek disconfirming evidence -- the single most effective tactic for turning AI-generated insights into reliable business decisions.
 audit_dataset() that takes a pandas DataFrame and checks for nulls, date ranges, and unique value counts. The terminal below shows the output of running the script on a sample CSV file." width="768" height="432" class="w-full rounded-lg shadow-md" loading="lazy" />
audit_dataset() that takes a pandas DataFrame and checks for nulls, date ranges, and unique value counts. The terminal below shows the output of running the script on a sample CSV file." width="768" height="432" class="w-full rounded-lg shadow-md" loading="lazy" />audit_dataset() that takes a pandas DataFrame and checks for nulls, date ranges, and unique value counts. The terminal below shows the output of running the script on a sample CSV file.Building these atomic skills requires more than a wishlist; it requires tactical prompts and constraints that force the AI into a skeptical mindset. The goal is to emulate the instinct of a seasoned analyst who looks at a dataset and immediately asks, "What's missing?" or "How could this be misleading?" By baking these questions into the skill criteria, you train the AI to adopt that mindset as a non-negotiable part of its process.
In my work testing various AI agents, the single most effective strategy is to mandate the search for disconfirming evidence. Most AI systems are optimized to find patterns that satisfy the query. You must explicitly task them with the opposite: find data that contradicts the emerging narrative. This simple switch transforms the AI from a cheerleader for a hypothesis into a rigorous peer reviewer.
How do you use the "Pre-Mortem" skill effectively?
Integrate a skill called "Conduct a Pre-Mortem on This Conclusion." After the AI produces a draft insight (e.g., "Feature X causes higher engagement"), the pass criteria for this skill are: "List three distinct reasons why this conclusion could be wrong, even if the data appears to support it." The AI must generate plausible alternative explanations, such as selection bias, seasonality, or an unmeasured third variable. This isn't about doubting everything; it's about stress-testing the insight's robustness before you stake resources on it. I've found that insights that survive a rigorous pre-mortem are 10x more likely to lead to successful outcomes.
Why should you force the AI to argue against itself?
Create a skill where the AI's task is "Draft a Counter-Argument." Assign it the role of a skeptical stakeholder (e.g., "Act as the Head of Finance who is budget-constrained. Write a 200-word critique of the recommendation to invest in Feature Y, based solely on the evidence presented."). To pass, the counter-argument must identify at least one logical flaw or unproven assumption in the original analysis. This role-playing forces the AI to examine its own reasoning from an adversarial perspective, surfacing weaknesses that a single, coherent narrative would gloss over. It's a form of internal debate that dramatically improves the final output's credibility.
What's the role of "Red Team" data sources?
A powerful advanced strategy is to build a skill that mandates the use of a "Red Team Data Source." This is an external or alternative dataset chosen specifically to challenge the primary one. The skill criteria could be: "Cross-reference the finding about mobile user growth with the quarterly report from App Annie's Data Hub (a market intelligence platform). Note any discrepancies between internal metrics and market benchmarks." By requiring the AI to seek out an authoritative external perspective, you break its myopic focus on internal data. It must reconcile differences, which often leads to deeper insights about measurement or market position.
How can you leverage AI to automate assumption tracking?
Finally, use the AI's own capabilities to create a living document. A skill titled "Generate an Assumptions Log" tasks the AI with maintaining a table of every assumption made during the analysis, from data definitions ("We assume a 'user' is defined by a unique cookie") to causal claims ("We assume increased ad spend causes awareness, not vice versa"). The pass/fail criteria require this log to be updated at each skill step. This creates an audit trail. When results are surprising, you can quickly review the log to see which assumption might have been invalid. This practice, borrowed from high-stakes fields like engineering and finance, brings necessary discipline to AI-driven exploration. For teams comparing different AI approaches, this rigorous method highlights why a comparison of Claude vs ChatGPT for complex, multi-step analysis often favors systems that can reliably follow such structured loops. If the bigger issue is that your Claude Code or Cursor sessions produce perfect code that fails in production, the same root cause -- missing contextual validation -- applies.
Putting Atomic Skills to Work: A Real-World Blueprint
A conversion-rate investigation using four sequenced Claude or Cursor skills -- from metric isolation to a weighted priority matrix -- demonstrates how atomic decomposition turns a vague "why are conversions down?" into a ranked, evidence-backed action plan.
Theory is one thing; implementation is another. Let's walk through a concrete blueprint for applying this method to a common business problem: declining website conversion rates. The goal is to move from a knee-jerk AI query to a structured investigation that yields reliable, actionable intelligence.
First, you wouldn't just ask your AI tool, "Why are conversions down?" Instead, you would create a Ralph Loop with a sequence of skills. The first skill, "Define Conversion and Diagnose the Drop," has strict pass criteria: the AI must 1) specify the exact conversion metric (e.g., "Proceed to Checkout" button click), 2) segment the drop by traffic source (organic, paid, direct), and 3) pinpoint the start date of the decline within a 3-day window. This alone prevents a wild goose chase—if the drop is isolated to paid social traffic starting July 15th, you're not debugging your entire website.
The next skill, "Audit Technical & Experience Factors," splits into parallel atomic tasks. One task is to analyze Core Web Vitals data from Google Search Console for degradation. The pass criteria require the AI to flag any metric (LCP, FID, CLS) that dropped below the "good" threshold near the conversion dip date. Another simultaneous task is to audit recent website changes via deployment logs or CMS history. The AI passes only if it can list every functional change made to the conversion funnel in the 7 days before the drop. This parallel investigation quickly separates technical regressions from content or UX issues.
With technical factors ruled in or out, the skill "Analyze User Behavior and Messaging Alignment" takes over. Here, you might task the AI with comparing session recordings (using a tool like Hotjar or FullStory) from before and after the drop, looking for new points of friction. A more nuanced task is to compare the marketing messaging on the landing pages (pulled from your CMS) against the value proposition in the driving ad campaigns (from Google Ads or Meta Ads Manager). The AI passes if it can identify a specific mismatch—for example, an ad promising a "free trial" but a landing page emphasizing "annual commitment."
Finally, the synthesis skill, "Prioritize Root Causes and Recommendations," uses a weighted scoring matrix. The AI must evaluate each potential cause (e.g., "slow LCP," "confusing pricing page," "ad-to-page mismatch") on three dimensions: evidence strength, impact on conversion, and ease of fix. The pass/fail criteria demand a ranked list with clear justification. The output isn't just "speed up your site"; it's "Priority 1: Fix the pricing page clarity (high evidence, high impact, easy fix). Priority 2: Investigate LCP increase for mobile users (medium evidence, high impact, medium fix)." This blueprint transforms a vague problem into a clear, prioritized action plan, with each step validated by the AI's ability to meet specific, verifiable criteria.
Got Questions About AI Data Analysis? We've Got Answers
Answers to the most common questions about using Claude, GPT-4, GitHub Copilot, and Cursor for structured, assumption-aware data analysis with atomic skill frameworks.
How often should I run these atomic skill checks on an AI analysis?You should run them every single time the analysis matters. For routine, low-stakes reporting (e.g., daily sales totals), a simple query is fine. But for any analysis that will inform strategy, resource allocation, or product changes—essentially any decision with a cost of being wrong—the atomic skill framework is your essential quality gate. It adds time upfront but saves orders of magnitude more time (and money) by preventing misguided actions. Think of it as the planning and peer review phase that separates robust research from a quick, potentially flawed, guess.
What if my AI tool can't handle multi-step tasks or pass/fail criteria?This is a key limitation of many conversational AI tools designed for single-turn Q&A. They aren't built to maintain state across a complex workflow or to evaluate their own output against criteria. This is precisely the gap that tools like the Ralph Loop Skills Generator are designed to fill. If your current AI can't do it, you have two options: manually break the process down yourself and guide the AI step-by-step (which is labor-intensive), or use a platform that specializes in structuring AI workflows. The capability to follow a loop with verification is what distinguishes an AI assistant from an AI analyst.
Can I use this method with any AI model, like ChatGPT or Claude?The core principle is model-agnostic, but the reliability varies significantly. Simpler models may struggle with the meta-cognition required for tasks like "generate competing hypotheses" or "conduct a pre-mortem." More advanced models like Anthropic's Claude 3.5 Sonnet, OpenAI's GPT-4o, and tools like Cursor or GitHub Copilot are far more capable of this kind of structured, critical thinking. The method will work best with models that have strong reasoning and instruction-following capabilities. The key is to be explicit in your criteria and to check the output rigorously. The method improves results with any model, but it turns a capable model into a truly reliable partner.
What's the biggest mistake teams make when starting with AI analysis?The biggest mistake is treating the AI as a replacement for human judgment rather than a tool to augment it. They ask a big, fuzzy question, get a big, confident-sounding answer, and run with it. They skip the "dumb" foundational questions about data quality and problem definition because the AI seems so smart. This is the automation bias trap. The correct approach is inverse: start with more skepticism, not less. Use the AI to rigorously pressure-test the problem space before seeking a solution. The human's job shifts from doing the analysis to designing and overseeing a process of analytical inquiry.
Ready to stop getting blindsided by your AI's analysis?
Ralph Loop Skills Generator turns your AI into a methodical analyst that questions data before jumping to conclusions. Build your first atomic skill loop today and ensure your next data-driven decision is built on rock-solid reasoning, not statistical mirages. Generate Your First Skill<!-- sister-projects-start -->
Other Doved Studio projects
Related tools from the same studio you might find useful:
- Glean: Turn scrolling time into a daily action plan. Capture, process, execute.
- Popout: Create your portfolio in minutes with a single shareable page.
- Larpable: Spot fake founders, guru grifts, and performance entrepreneurship.
- Doved Studio: Studio indie derrière cette app et une dizaine d'autres outils.
ralph
Building tools for better AI outputs. Ralphable helps you generate structured skills that make Claude iterate until every task passes.