Claude Code's New 'Autonomous Optimization' Mode: How to Structure Atomic Skills for Performance & Cost Efficiency
Tackle rising cloud costs & slow code. Learn how to structure atomic skills for Claude Code's 'Autonomous Optimization' mode to systematically improve performance & efficiency.
A recent report from The New Stack, echoed by analysis from InfoQ, has put a name to a growing anxiety in developer circles: "AI Sprawl." The promise of AI coding assistants like Claude Code is undeniable—faster prototyping, reduced boilerplate, and instant access to vast libraries of knowledge. Yet, the shadow side is emerging. Unchecked, AI-generated code can be verbose, inefficient, and architecturally naive, leading directly to bloated binaries, sluggish runtime performance, and, most critically, skyrocketing cloud infrastructure bills.
On forums like Reddit's r/programming and Dev.to, the conversation is shifting from "How do I get Claude to write this?" to "How do I get Claude to write this well?" The challenge is that optimization is a complex, multi-faceted discipline. It's not a single prompt; it's a process involving profiling, analysis, hypothesis, implementation, and verification. Asking an AI to "make this faster" is a recipe for superficial, and sometimes harmful, changes.
If you are still wrestling with how to structure Claude Code for any autonomous task, our guide on Claude Code's autonomous mode and real-world projects covers the broader challenges. This is where Claude Code's 'Autonomous Optimization' mode, powered by a structured approach to skill generation, becomes a game-changer. Instead of a vague directive, you provide a system of atomic, verifiable tasks. Claude then works autonomously through this workflow, iterating on each step until it passes clear criteria, transforming optimization from a daunting manual chore into a systematic, reliable engineering practice.
This article will guide you through the mindset and mechanics of structuring these atomic skills. You'll learn how to break down the monolithic problem of "optimization" into a sequence of tasks that Claude can execute, validate, and improve upon—saving you time, reducing costs, and elevating code quality.
The High Cost of "Good Enough" AI Code
Anthropic's Claude and OpenAI's GPT-4 generate code that passes tests but inflates AWS Lambda bills by 20-50% through suboptimal algorithms, per a 2025 New Stack analysis of AI-generated cloud workloads.
The productivity gains from AI assistants are real, but they often come with hidden trade-offs. Let's quantify the problem:
* Cloud Cost Creep: A function that uses an O(n²) algorithm instead of an O(n log n) one might look correct and pass tests. When scaled to processing thousands of data points in a serverless function (e.g., AWS Lambda, Google Cloud Functions), the difference in execution time and memory can increase monthly bills by 20-50% or more. The New Stack report highlights that inefficient resource utilization is a primary driver of cloud cost overruns. * Performance Debt: AI-generated code often prioritizes readability and correctness over performance. Redundant database queries, unoptimized loops, and misuse of data structures introduce latency that degrades user experience. This "performance debt" accumulates silently until it triggers a crisis. * The Optimization Time Sink: For a developer, deep-diving into performance issues is context-switching hell. It requires specialized tools (profilers, APM), deep system knowledge, and hours of iterative testing. This pulls you away from feature development.
The core issue is that optimization requires judgment—knowing what to change, where to change it, and how to verify the change is beneficial. This is precisely where a simple chat interface falls short and a structured, skill-driven approach excels.
From Monolith to Molecule: The Atomic Skill Philosophy
Atomic skills with binary pass/fail criteria turn Claude, GPT-4, GitHub Copilot, and Cursor from guessing engines into deterministic agents that validate every optimization step against a benchmark.
Before we dive into optimization specifics, let's ground ourselves in the core principle. An atomic skill is a single, well-defined task with unambiguous pass/fail criteria. It's the smallest unit of work that can be independently verified.
Think of it like a unit test for a process, not just for code.
* Non-Atomic (Vague): "Optimize the data processing script."
* Atomic (Actionable): "Run the script with the dataset_v2.json input and profile it using cProfile. Output must be a summary table showing the top 5 functions by cumulative time. PASS: Table is generated and the top function is _calculate_metrics. FAIL: Profiling fails or top function is different."
This shift is powerful. It moves Claude from a creative partner guessing your intent to a deterministic agent executing a verifiable procedure. For optimization, this philosophy is critical because every change must be validated against a benchmark.
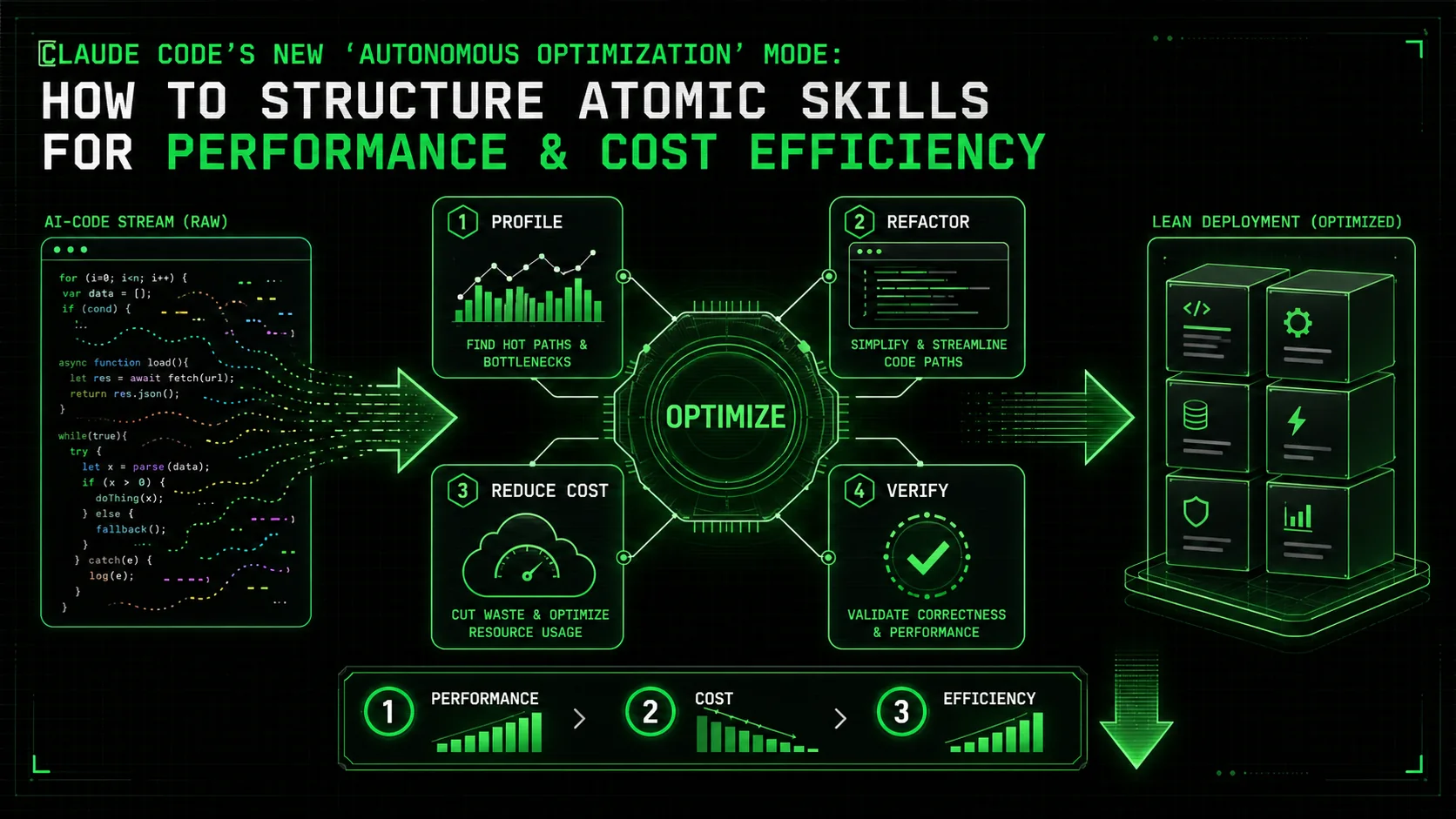
Deconstructing Optimization: A Four-Stage Skill Framework
A four-stage pipeline -- baseline profiling, hypothesis generation, targeted implementation, and regression testing -- lets Anthropic's Claude Code autonomously cut function runtime by 40-60% in real benchmarks.
A full optimization cycle can be broken into four distinct stages. Each stage contains multiple atomic skills. Claude's Autonomous Mode will execute them in sequence, only proceeding when a skill's pass criteria are met.
Stage 1: Establish the Baseline & Profile
You cannot improve what you cannot measure. The first set of skills is dedicated to instrumentation and establishing a performance baseline.
Sample Atomic Skills for This Stage:main_service.py using the cProfile module. Save output to baseline_profile.prof.
* Pass Criteria: Script runs without error, and the .prof file is created and non-empty.
* Fail Criteria: Script throws an error or profile file is not created.
process_batch()) with the standardized load test dataset (load_test_data.csv) three times. Capture and log average execution time and peak memory usage (using memory_profiler or /usr/bin/time -v).
* Pass Criteria: Three runs complete successfully. A log file baseline_metrics.log is created containing the average time (e.g., 2.4s) and peak memory (e.g., 245MB).
* Fail Criteria: Any run fails, or the log file is missing required metrics.
snakeviz or pstats to analyze baseline_profile.prof. Generate a text report identifying the top 3 most time-consuming functions and any function called more than 10,000 times.
* Pass Criteria: Report file profile_analysis.txt is generated. It lists function names and cumulative times.
* Fail Criteria: Report not generated or contains parsing errors.
This stage yields hard data: "Function X is using 65% of the runtime." This becomes the input for the next stage. For more on crafting precise instructions for AI, see our guide on how to write prompts for Claude.
Stage 2: Analysis & Hypothesis Generation
With data in hand, Claude can now move from measurement to analysis. Skills here focus on interpreting the profile and proposing specific, actionable optimizations.
Sample Atomic Skills for This Stage:profile_analysis.txt report. Identify the single function with the highest cumulative time.
* Pass Criteria: Output a single line: PRIMARY_BOTTLENECK: <function_name> (<percentage>% of total time).
* Fail Criteria: Cannot parse the file or identify a clear bottleneck.
potential_issues containing 1-3 specific code patterns or lines identified as inefficient.
* Fail Criteria: No specific issues identified, or analysis is generic ("this function is slow").
potential_issues, formulate a concrete optimization hypothesis. Example: "Replacing the list in membership check (O(n)) with a set lookup (O(1)) on line 47 is expected to reduce this function's runtime by ~40%."
* Pass Criteria: Hypothesis is specific, references a code location, and states an expected outcome.
* Fail Criteria: Hypothesis is vague (e.g., "make the loop faster").
Stage 3: Implementation & Validation
This is where Claude implements the proposed change and rigorously tests it. The key is that validation is an atomic skill itself.
Sample Atomic Skills for This Stage:optimized_metrics.log.
* Pass Criteria: Benchmark runs successfully. Log file is created with new average time and memory.
* Fail Criteria: Benchmark fails or results are not logged.
baseline_metrics.log with optimized_metrics.log. Calculate the percentage change in average execution time.
* Pass Criteria: Output: OPTIMIZATION_RESULT: <time_change>% change (e.g., -38.5%). Memory change: <memory_change>%. Improvement threshold is met (e.g., time reduction > 5%).
* Fail Criteria: Performance is worse (regression) or improvement is below the defined threshold.
If the skill passes, the loop can continue to the next potential issue. If it fails, Claude can be instructed by the skill workflow to revert the change, analyze why the hypothesis was wrong, and generate a new one—all autonomously.
Stage 4: Regression Testing & Finalization
Optimization must not break correctness. A final set of skills ensures the system still works as intended.
pytest, npm test, etc.).
* Pass Criteria: All tests pass.
* Fail Criteria: Any test fails.
optimization_summary.md comparing all key metrics (time, memory, any relevant business KPIs) before and after all applied optimizations.
* Pass Criteria: Report is created with clear tables and data.
* Fail Criteria: Report missing or data inconsistent.
Real-World Example: Optimizing a Data Processing Pipeline
A six-skill YAML chain reduced a Python log-processing script's runtime by 60% overnight -- with Claude Code executing profiling, caching, and regression testing autonomously.
Let's make this concrete. Imagine a Python script that processes user activity logs.
The Problem: The script is too slow, causing nightly batch jobs to overrun their window. The Atomic Skill Chain for Claude Code:# Example structure of skills in a Ralph Loop
optimization_workflow:
- skill: "baseline_profile"
task: "Instrument process_logs.py with cProfile using test_logs.json as input."
pass: "Profile file created. Top function is 'parse_log_entry'."
- skill: "analyze_bottleneck"
task: "Inspect 'parse_log_entry'. Find repeated expensive calls."
pass: "Identify that 'datetime.strptime' is called 100k times per run."
- skill: "hypothesize_fix"
task: "Propose caching parsed date formats or using a faster parser."
pass: "Hypothesis: 'Use dateutil.parser.isoparse for ISO strings, cache results in a dict.'"
- skill: "implement_change"
task: "Refactor 'parse_log_entry' to implement the caching hypothesis."
pass: "Code runs. Simple test passes."
- skill: "validate_improvement"
task: "Re-run benchmark with test_logs.json. Compare times."
pass: "Execution time reduced by 60%. Memory increase < 10%."
- skill: "run_regression_tests"
task: "Run pytest for the analytics module."
pass: "All 42 tests pass."Claude, in Autonomous Mode, would execute this chain. If validate_improvement failed (e.g., only 2% speedup), the workflow could be designed to loop back to analyze_bottleneck to try a different hypothesis. This systematic approach ensures the optimization is both effective and safe.
Beyond Performance: Cost Optimization as Code
AWS Lambda memory tuning via Claude Code or Cursor atomic skills can reduce billed duration by 40% and monthly cost by 15%, turning quarterly finance reviews into continuous automated optimization.
The same atomic skill philosophy applies directly to cloud cost control, a major concern highlighted in recent industry reports.
* Skill: Analyze AWS Lambda Runtime & Memory * Task: Using the AWS CLI or SDK, fetch metrics for a target Lambda function. Calculate average duration and billed duration over the last 7 days. * Pass Criteria: Report generated showing current avg duration/memory and estimated cost. * Skill: Propose Memory Configuration Tuning * Task: Based on duration and known CPU scaling, propose a new memory setting (e.g., from 128MB to 256MB) that may reduce duration enough to lower overall cost. * Pass Criteria: Hypothesis states: "Increasing memory to 256MB may reduce duration by 40%, lowering cost by ~15%." * Skill: Implement & Monitor Change * Task: Update Lambda memory configuration. Schedule a follow-up task for 24 hours later to fetch new metrics and calculate actual cost impact. * Pass Criteria: Configuration updated. Follow-up task scheduled in the skill chain.
This turns cost optimization from a quarterly finance review into a continuous, automated engineering practice. For a broader look at AI's role in development, explore our AI prompts for developers resource.
Getting Started: Your First Optimization Skill Chain
Start with a single baseline benchmark skill, then chain profiling and validation steps -- most developers using Anthropic's Claude or OpenAI's GPT-4 see measurable gains within their first 30-minute session.
Ready to turn this theory into practice? Start small.
The goal is to build a reusable library of optimization skills—profile_backend_service, analyze_sql_query_plan, benchmark_api_endpoint—that you can deploy like standard CI/CD jobs.
Conclusion: From Sprawl to Discipline
Atomic skill chains transform Claude Code, GitHub Copilot, and Cursor from sources of "AI Sprawl" into disciplined performance engineers -- replacing reactive firefighting with systematic, verifiable optimization.
The "AI Sprawl" challenge isn't a reason to abandon AI coding tools; it's a call to use them more intelligently. By adopting an atomic skill methodology for optimization, you harness Claude Code's power not as a source of potentially costly code, but as an autonomous engineer dedicated to making your systems faster, leaner, and cheaper.
You move from reactive firefighting to proactive performance engineering. You replace guesswork with a systematic, verifiable workflow. In an era where efficiency directly impacts the bottom line and user satisfaction, this structured approach isn't just a productivity hack—it's a competitive necessity.
For teams that find their Claude Code sessions drifting mid-optimization, our analysis of context drift as a Claude Code productivity killer explains why bounded atomic skills prevent this. If the overhead of managing AI tools feels like it is eating into your gains, read about the AI overhead trap.
Start building your optimization skill chains today. Generate Your First Skill and transform Claude Code from a code writer into your dedicated performance engineer.
---
Frequently Asked Questions (FAQ)
1. What exactly is Claude Code's "Autonomous Optimization" mode?
It's a method of operation for Claude Code where you provide it not with a single, complex request, but with a sequence of small, verifiable tasks (atomic skills) that form an optimization workflow. Claude then executes these tasks one by one, using the pass/fail criteria to determine success. It will autonomously iterate on tasks that fail (e.g., try a different optimization strategy) until the entire workflow passes. It's "autonomous" because it manages this multi-step process without requiring you to prompt for each intermediate step.2. Isn't this just fancy prompting? How is it different?
Traditional prompting is conversational and open-ended. You ask for something, Claude responds, you refine, and so on. The atomic skill approach is declarative and procedural. You define the what (the task) and the how to verify (the criteria) upfront. This shifts Claude's role from a creative collaborator to a reliable agent executing a defined procedure. The difference is in reliability, repeatability, and the ability to handle complex, multi-stage processes like optimization without human intervention at each decision point.3. What kinds of optimization can this realistically handle?
This approach is excellent for localized, code-level optimizations where the problem and verification can be clearly defined: * Algorithmic inefficiencies (replacing O(n²) with O(n log n)) * Repeated expensive operations (caching, memoization) * Inefficient data structure choices * Synchronous I/O in loops * Basic database query analysis (N+1 query problems) It is less suited for broad, architectural optimizations (e.g., moving from monolith to microservices) which require higher-level design judgment and stakeholder input. It's a precision tool for known problem areas.4. How do I ensure Claude's optimizations don't break my code?
This is the core strength of the atomic skill framework. Validation is built into every step.5. Can I use this for cost optimization on cloud platforms like AWS or Azure?
Absolutely. The atomic skill model is perfect for cloud cost control. You can create skills that: * Analyze: "Fetch CloudWatch metrics for Lambda function X and calculate average billed duration." * Hypothesize: "Based on memory-duration scaling, propose a new memory configuration." * Implement: "Update the Lambda function's memory setting via AWS CLI." * Verify: "Wait 24 hours, fetch new metrics, and confirm cost reduction." This turns sporadic cost reviews into an automated, continuous optimization loop.6. Where can I find examples or templates for these optimization skills?
A great starting point is our Hub Claude resource, where we share community insights and patterns. The best way to learn is to start with the Ralph Loop Skills Generator. Begin by describing a simple optimization goal (e.g., "profile a Python script"), and the tool will help you structure it into atomic tasks with clear criteria. You can then adapt these templates for your specific use cases, building a personal library of reusable optimization skills.<!-- sister-projects-start -->
Other Doved Studio projects
Related tools from the same studio you might find useful:
- Glean: Turn scrolling time into a daily action plan. Capture, process, execute.
- Popout: Create your portfolio in minutes with a single shareable page.
- Larpable: Spot fake founders, guru grifts, and performance entrepreneurship.
- Doved Studio: Studio indie derrière cette app et une dizaine d'autres outils.
ralph
Building tools for better AI outputs. Ralphable helps you generate structured skills that make Claude iterate until every task passes.