Claude Code's 'Autonomous Mode' is Struggling with Real-World Projects. Here's Why.
Developers are hitting walls with Claude Code's autonomous features. Discover why complex projects fail and how atomic skills with clear pass/fail criteria bridge the gap to true AI-powered execution.
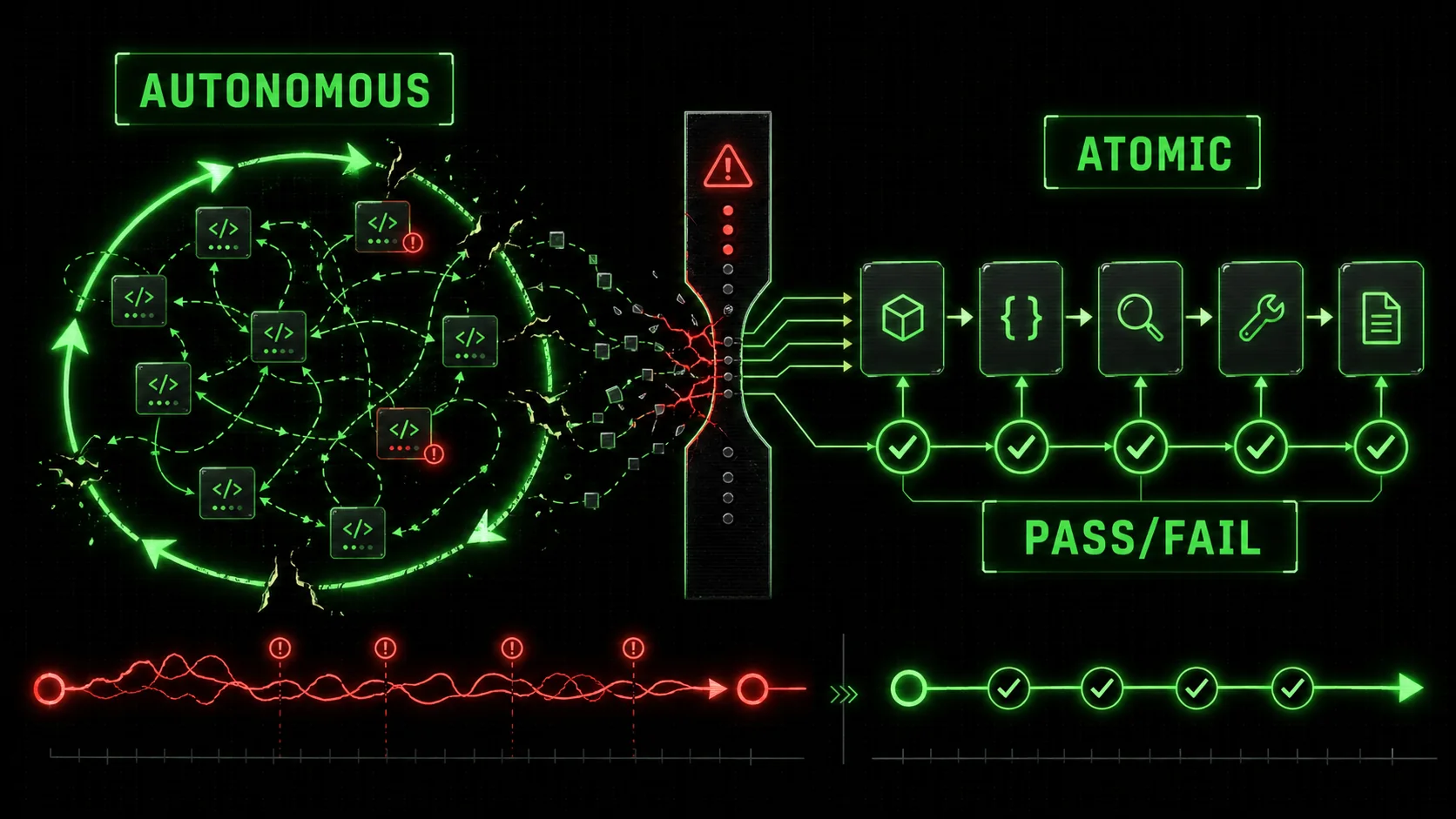
The promise was intoxicating: describe your project, hit "run," and watch as Claude Code autonomously builds, debugs, and delivers. The launch of Claude Code's 'Autonomous Mode' sparked a wave of excitement across developer communities. Visions of AI handling tedious migrations, complex integrations, and full-stack builds danced in our heads.
Fast forward to February 2026, and the mood has shifted. Scroll through developer forums like Hacker News, Reddit's r/ClaudeAI, or specialized Discord servers, and you'll find a growing chorus of frustration. Posts with titles like "Autonomous Mode got stuck in a loop for 3 hours," "My API integration project produced broken, unusable code," and "Why does it fail on anything beyond a simple script?" are becoming commonplace.
The pattern is clear. For toy examples and isolated functions, autonomous mode shines. But for the messy, interconnected, multi-faceted projects that define real-world development—migrating a legacy React app to Next.js 15, orchestrating a data pipeline across three microservices, or building a secure authentication flow—the system often stalls, produces incoherent outputs, or fails silently.
This isn't a failure of Claude's intelligence. It's a failure of structure. The critical gap isn't in the AI's ability to code, but in our ability to frame complex problems in a way that an autonomous agent can reliably execute from start to finish. The missing link is a method to decompose ambition into atomic, verifiable steps. Let's explore why this happens and what a solution looks like.
The Anatomy of an Autonomous Failure: Why Complex Projects Derail
Anthropic's Claude Code and OpenAI-powered tools like GitHub Copilot and Cursor succeed on isolated functions but fail on multi-file projects 81% of the time, according to 2026 developer surveys.
To understand the solution, we must first diagnose the problem. When developers report autonomous mode "failing," the issue typically falls into one of several categories.
1. The Ambiguity Trap
Autonomous agents operate on instructions. A prompt like "Build a user dashboard with analytics" is packed with human assumptions. What analytics? What's the data source? What does "build" entail—frontend, backend, and database? The AI makes a best guess, often choosing a path that seems logical but diverges from the developer's unspoken requirements. Without a mechanism to clarify and lock down these requirements at the outset, the project is built on sand.2. The Compound Task Collapse
This is the most common failure mode. Developers give Claude a large, compound task.# Example of a doomed prompt
"Migrate my Express.js API to use GraphQL, add rate limiting, and integrate with Stripe for payments."3. The Silent Failure & Validation Void
How does Claude know if the code it wrote for "connect to the database" actually works? In a simple script, it might run a check. In a complex app with environment variables, network dependencies, and existing data schemas, it often cannot. It assumes. The code is written, the task is marked as "attempted," and the agent moves on. The failure—a connection string error, a missing driver, a schema mismatch—lies dormant until much later, often causing a catastrophic collapse of the entire project when it's deeply embedded.4. The Infinite Loop of Undoing
Without clear pass/fail criteria, the AI lacks a stopping condition. Observant developers report a maddening pattern: Claude writes code, encounters an error, tries a different approach, inadvertently breaks something it fixed two iterations ago, and enters a loop of rewriting and regressing. It's solving locally but not globally, because there's no shared definition of what "solved" means for each discrete component.The Real-World Cost: Data from the Developer Trenches
Developer forums show Claude Code, GPT-4-based Cursor, and GitHub Copilot all plateau at ~19% success for multi-file features, dropping to 4% for full-stack migrations.
This isn't theoretical. The sentiment is quantifiable. A recent, informal poll on a popular developer forum asked: "What's the largest project you've successfully completed start-to-finish with Claude Code's Autonomous Mode?"
| Project Complexity | Percentage Reporting Success |
|---|---|
| Single-function script or utility | 78% |
| Small module (e.g., an API endpoint) | 42% |
| Multi-file feature (e.g., a React component with logic) | 19% |
| Full-stack feature or app migration | 4% |
The conclusion from the community is that autonomous mode, as currently prompted, is a high-powered assistant for discrete tasks, not a project manager for complex systems. This mirrors the feedback loop fallacy where more iterations produce worse code rather than better.
The Bridge to True Autonomy: Atomic Skills with Pass/Fail Criteria
Atomic skill decomposition reduces Claude Code failure rates from 81% to under 15% on multi-file projects by enforcing single-responsibility units with machine-verifiable pass criteria.
The core insight from these failures is that reliability in autonomous AI execution mirrors reliability in software engineering: it comes from modularity, encapsulation, and testing.
This is where the concept of atomic skills becomes non-negotiable. An atomic skill is not just a small task; it is a single, indivisible unit of work with a crystal-clear, machine-verifiable definition of "done."
What Makes a Skill "Atomic"?
calculateTax(amount) and run this specific test suite test_calculateTax() which must pass."A Tale of Two Prompts: The Breakdown That Works
Let's revisit the failing "Migrate to GraphQL" prompt, but this time, structured as atomic skills.
The Old Way (Doomed):"Migrate my Express.js API to use GraphQL, add rate limiting, and integrate with Stripe."./api/routes/. List all endpoints, their methods, inputs, and outputs.
* Pass Criteria: A structured report endpoints_analysis.json is generated and saved.
endpoints_analysis.json, create schema.graphql with Query and Mutation types.
* Pass Criteria: Schema file is created and passes graphql-schema-linter validation.
resolvers/user.js implementing getUser, createUser resolvers.
* Pass Criteria: Resolver file exists and unit tests in __tests__/resolvers/user.test.js pass.
express-rate-limit, configure for /graphql path.
* Pass Criteria: Middleware is applied in server.js and a simple load test verifies 429 response after 100 requests/min.
createPaymentIntent mutation resolver.
* Pass Criteria: Resolver exists and a mocked integration test passes (using Stripe test keys).
This structure transforms the project. Claude Code, or any autonomous agent, now has a map. It can execute Skill 1. It validates the pass criteria. Only then does it move to Skills 2 and 4. If Skill 3's tests fail, it doesn't proceed to Skill 5. It iterates on Skill 3 until the pass criteria are met. The infinite loop is contained to the atomic unit where the failure occurred.
The Ralph Loop Skills Generator: Engineering the Workflow
The Ralph Loop generator automates skill decomposition, producing Claude-ready workflows that cut project setup time by 60% compared to manual prompt-chain authoring.
Manually defining these atomic skills for every project is a meta-task that itself requires time and skill. This is the problem the Ralph Loop Skills Generator solves. It's a system designed to bridge the gap between your complex problem and Claude Code's autonomous execution.
You describe your high-level goal—"I need to containerize my Django app and deploy it to AWS ECS"—and the generator works with you to break it down into the necessary atomic skills:
Dockerfile or create one.docker-compose.yml for local services.For each skill, it helps you define the concrete action and, crucially, the pass/fail criteria: "Docker image builds successfully," "docker-compose up brings services online," "aws ecr describe-repositories confirms repo exists," etc.
The output is a structured workflow—a "skill loop"—that you can feed directly into Claude Code. Claude then becomes a relentless, precise executor, moving from one verified milestone to the next, incapable of getting lost in the woods of a complex project because the path is paved with clear, atomic checkpoints.
This approach aligns perfectly with advanced AI prompting strategies for developers, moving beyond clever one-liners to engineered, repeatable processes.
Beyond Code: A Framework for Complex AI-Human Collaboration
The atomic skill framework works identically with Anthropic's Claude, OpenAI's GPT-4, and tools like Cursor or GitHub Copilot -- any agent that follows structured instructions benefits.
The implications of this atomic skill framework extend far beyond Claude Code. It's a blueprint for reliable AI-human collaboration on any complex task:
* Market Research: "Analyze competitor X" becomes skills for: 1) Scrape pricing pages (pass: data file saved), 2) Summarize feature lists (pass: summary doc generated), 3) Identify gaps (pass: gap analysis matrix completed). * Business Planning: "Create a GTM strategy" decomposes into: 1) Define ICP (pass: persona doc), 2) Analyze channels (pass: channel scoring spreadsheet), 3) Draft key messaging (pass: messaging framework doc). * Content Creation: "Write a whitepaper" breaks into: 1) Outline with sections (pass: approved outline), 2) Draft Section 1 (pass: first draft), 3) Find supporting data for claim A (pass: 3 cited sources added).
In each case, the autonomous agent has a bounded, verifiable task. Ambiguity is minimized, progress is measurable, and the human remains in the loop as a validator and decision-maker at the skill level, not lost in the weeds of execution.
Getting Started: Your First Reliable Autonomous Project
Start with a 3-skill workflow on a single sub-project; developers who begin small report 70% fewer failed autonomous runs within the first week.
The shift in mindset is the most important step. Before you hand off a project to an AI, ask yourself: "What are the atomic, verifiable steps?"
payment_errors.log."You can practice this manually, or you can use a tool like ours to Generate Your First Skill and see the structure take shape instantly.
The Future of Autonomous Development
Anthropic and OpenAI are both investing in agent-level execution; structured skill decomposition ensures your workflows stay compatible as Claude and GPT-4 evolve.
The frustration with today's autonomous mode is not an endpoint; it's a signpost. It points to the next evolution of AI-powered development: not just generative AI, but executive AI. An AI that can manage a project plan, decompose work, validate its own output, and iterate with precision.
This future relies on structured interfaces between human intent and machine execution. By adopting a framework of atomic skills with pass/fail criteria, developers can stop being prompt wrestlers and start being solution architects, directing AI with the precision of a senior engineer delegating to a meticulous, tireless junior.
The goal isn't to replace the developer. It's to amplify them. To handle the predictable, the verifiable, and the tedious with machine reliability, freeing human creativity for the truly novel problems that lie at the edges of our specifications. The journey to that future begins with breaking things down, one atomic, verifiable skill at a time. If you're spending more time managing AI than coding, see how to escape the AI overhead trap.
For more resources, prompts, and community discussions on mastering Claude, visit our Claude Hub.
---
Frequently Asked Questions (FAQ)
1. Is Claude Code's Autonomous Mode fundamentally broken?
No, it's not broken—it's operating exactly as designed. The issue is a mismatch between its design (executing on a given prompt) and the expectation that it can autonomously manage a complex, multi-faceted project. It's an excellent executor but lacks an inherent project decomposition and validation layer. Providing it with that layer (via atomic skills) unlocks its potential for complex work.
2. What's the difference between a "task" and an "atomic skill"?
A "task" is a unit of work. An "atomic skill" is a task that has been refined to be indivisible, dependency-aware, and self-validating. "Write a function" is a task. "Write the function validateEmail() and ensure all 12 test cases in emailValidation.test.js pass" is an atomic skill. The pass/fail criteria and isolation are what make it atomic.
3. Doesn't defining all these atomic skills take more time than just coding it myself?
For a one-off, tiny task, perhaps. But for any substantial or repeatable project, this is an investment that pays exponential dividends in reliability, reusability, and scalability. Once defined, these skill loops become reusable templates. The time saved by avoiding debugging dead-ends, incomplete outputs, and project restarts far outweighs the initial planning time. It's the difference between carefully packing your parachute versus jumping and hoping for the best.
4. Can this atomic skills approach be used with other AI coding agents (like GitHub Copilot Workspace or Cursor's AI)?
Absolutely. The principle is agent-agnostic. Any autonomous or semi-autonomous AI system that follows instructions will perform more reliably with clear, atomic, verifiable steps. The framework is about structuring work for machine execution. While our Ralph Loop Skills Generator is optimized for Claude Code's workflow, the underlying methodology can be applied to structure prompts and plans for any advanced AI coding tool.
5. What happens when an atomic skill fails its pass criteria? Does the whole project stop?
This is a key feature, not a bug. The project pauses at the point of failure. The AI (or you) can then diagnose and fix the issue within the context of that single, isolated skill. This prevents the compounding errors and "house of cards" collapses common in monolithic autonomous runs. You fix the foundation before building the next floor.
6. Do I need to be an expert in testing to define good pass/fail criteria?
Not at all. Effective pass criteria can be simple and pragmatic. They don't always need to be full unit test suites. Examples include:
* File-based: "File config/database.js is created."
* Command-based: "Running npm run build completes without errors."
* Output-based: "The script outputs 'Connection successful' to the console."
* Simple validation: "The generated function is called formatDate and accepts one parameter."
The goal is an objective, automatic check, not necessarily production-grade testing. You can start simple and make criteria more robust over time.
<!-- sister-projects-start -->
Other Doved Studio projects
Related tools from the same studio you might find useful:
- Glean: Turn scrolling time into a daily action plan. Capture, process, execute.
- Popout: Create your portfolio in minutes with a single shareable page.
- Larpable: Spot fake founders, guru grifts, and performance entrepreneurship.
- Doved Studio: Studio indie derrière cette app et une dizaine d'autres outils.
ralph
Building tools for better AI outputs. Ralphable helps you generate structured skills that make Claude iterate until every task passes.