Is Your AI Assistant's 'Strategic Planning' Actually Just Guessing?
Is your AI's business strategy just sophisticated guessing? Learn how to apply atomic tasks and pass/fail criteria to transform Claude Code into a reliable strategic partner for 2026.
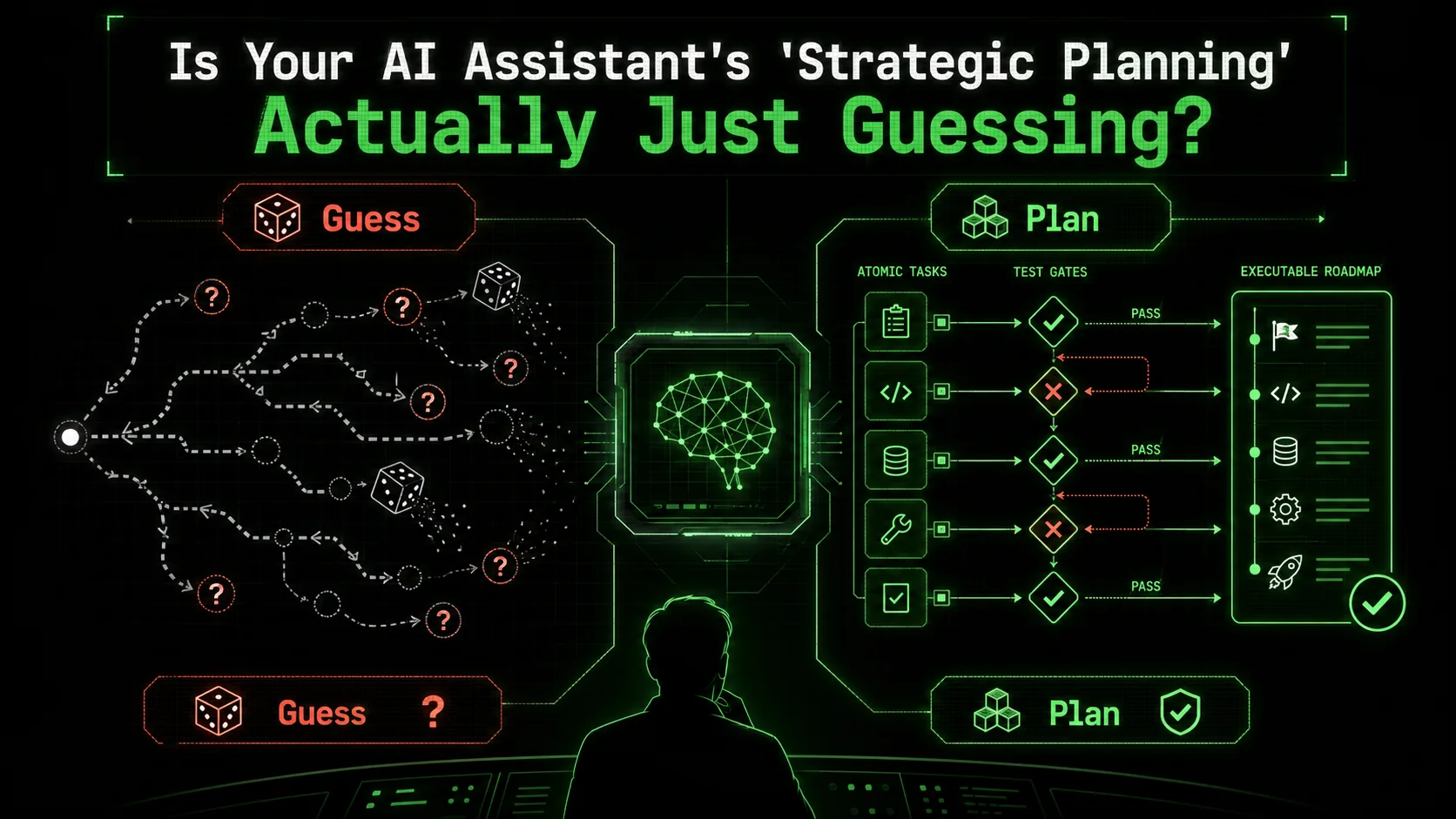
You’ve just asked your AI assistant to draft a go-to-market strategy for a new product. A minute later, you’re staring at a 2,000-word document. It’s structured, it’s confident, and it uses all the right buzzwords: “synergy,” “leveraging core competencies,” “optimizing the customer journey.” It sounds strategic. But when you try to pin down how to execute step three, or what metric definitively proves step five worked, the plan gets fuzzy. The AI can’t tell you. It generated a narrative, not a workflow. It made a series of educated, probabilistic guesses about what a good strategy document looks like, stitched them together with convincing language, and presented it as a plan.
This is the silent crisis in AI-assisted business strategy. As a 2026 TechCrunch analysis noted, reliance on AI for strategic planning is surging, but so are reports of “strategic drift”—teams following AI-generated directions that sound plausible but lead to dead ends or wasted resources. The latest Claude models from Anthropic have dramatically improved at complex, multi-step reasoning -- outpacing OpenAI’s GPT-4 on several planning benchmarks -- but that raw capability doesn’t automatically translate to reliable business application. The gap isn’t in the AI’s intelligence; it’s in the interface between human intent and machine execution. We’re asking for plans, and getting prose. We need a system that forces vagueness into verifiability.
The solution isn’t better prompts for “more detailed” strategies. It’s a fundamental shift from treating the AI as a document generator to treating it as an iterative workflow engine. This is where the methodology of atomic tasks with pass/fail criteria changes everything. By breaking a monumental problem like “enter a new market” into a sequence of tiny, testable jobs, you transform Claude Code from a strategic guesser into a strategic partner that works, checks, and iterates until every single component of the plan is validated. Let’s examine why the current approach fails and how to build a strategy you can actually trust.
What Is AI-Guessed Strategy (And Why It Feels So Real)
Claude, GPT-4, and GitHub Copilot generate strategies by pattern-matching millions of business plans -- producing documents that look authoritative but lack verifiable logic and measurable pass/fail criteria.
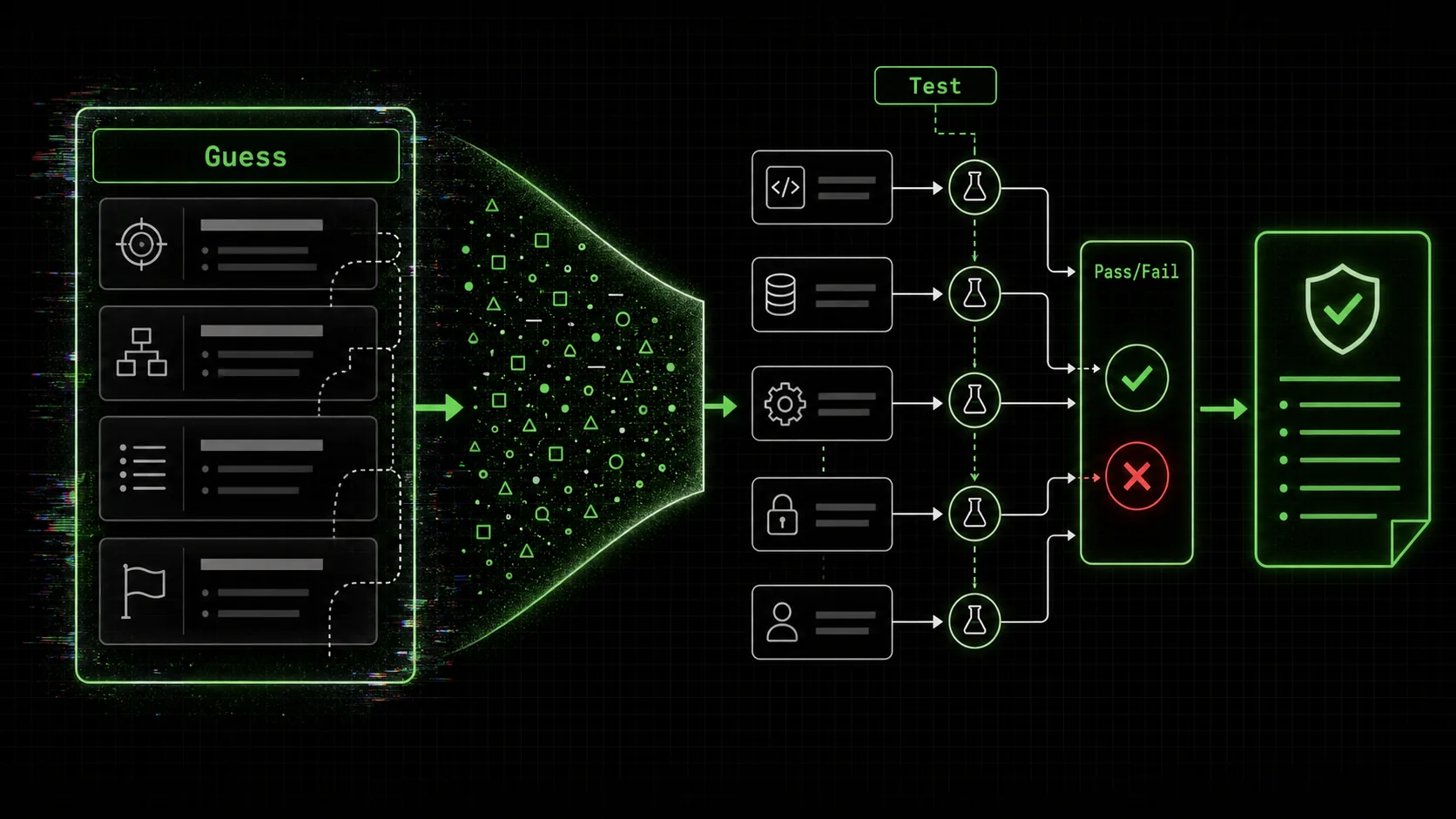
When you ask an AI to “create a strategy,” what it’s actually doing is pattern matching. It scans its vast training data—millions of business plans, consulting reports, blog posts, and case studies—and identifies the most statistically likely sequence of words and concepts to follow your request. The output is a simulacrum of strategy: it has the shape, tone, and structure of a real plan, but it often lacks the connective tissue of actionable logic and measurable validation. I call this “AI-guessed strategy.” It’s not malicious or lazy; it’s a natural outcome of how large language models generate text.
The feeling of authenticity is powerful. The AI uses authoritative language, cites plausible data points (often fabricated unless specifically guided otherwise), and structures arguments logically. This is why a solopreneur or a busy product manager might accept the first draft. The document looks finished. But under the surface, critical elements are missing or ungrounded.
The Hallmarks of a Guessed Strategy: * Vague Success Criteria: “Increase brand awareness” or “improve customer engagement.” How much? Measured by what? By when? Implied but Unexamined Logic: “We will use LinkedIn Ads to reach decision-makers.” Is that where your* specific decision-makers actually spend their time? Has this been validated? * Monolithic Tasks: “Conduct competitive analysis.” This is a 40-hour project, not a single, completable task. There’s no clear “done.” * No Built-in Verification: The strategy is a linear document. There’s no mechanism for the AI to check if a step is correct or feasible before proceeding to the next one.Contrast this with a strategy built from atomic tasks. An atomic task is a single, irreducible unit of work with a crystal-clear definition of “done.” It has a binary, pass/fail outcome based on objective criteria. “Find and list the top 5 competitors by market share in the US fintech SaaS space, with their primary pricing page URL” is atomic. You can verify it. “Understand the competitive landscape” is not.
| AI-Guessed Strategy | Atomic Task Strategy |
|---|---|
| Output is a persuasive document. | Output is a verifiable workflow. |
| Success is defined by textual coherence. | Success is defined by passing objective checks. |
| Linear and monolithic. | Iterative and modular. |
| The AI’s role ends at generation. | The AI’s role is to execute and validate. |
| Risk of “strategic drift” is high. | Progress is grounded in empirical checks. |
Why "Plausible" AI Strategy Is a Business Risk
Unverified AI strategies from Anthropic's Claude or OpenAI's GPT-4 create false consensus, accountability vacuums, and resource sinkholes -- PMI data shows poorly defined AI-generated requirements are a leading cause of project failure.
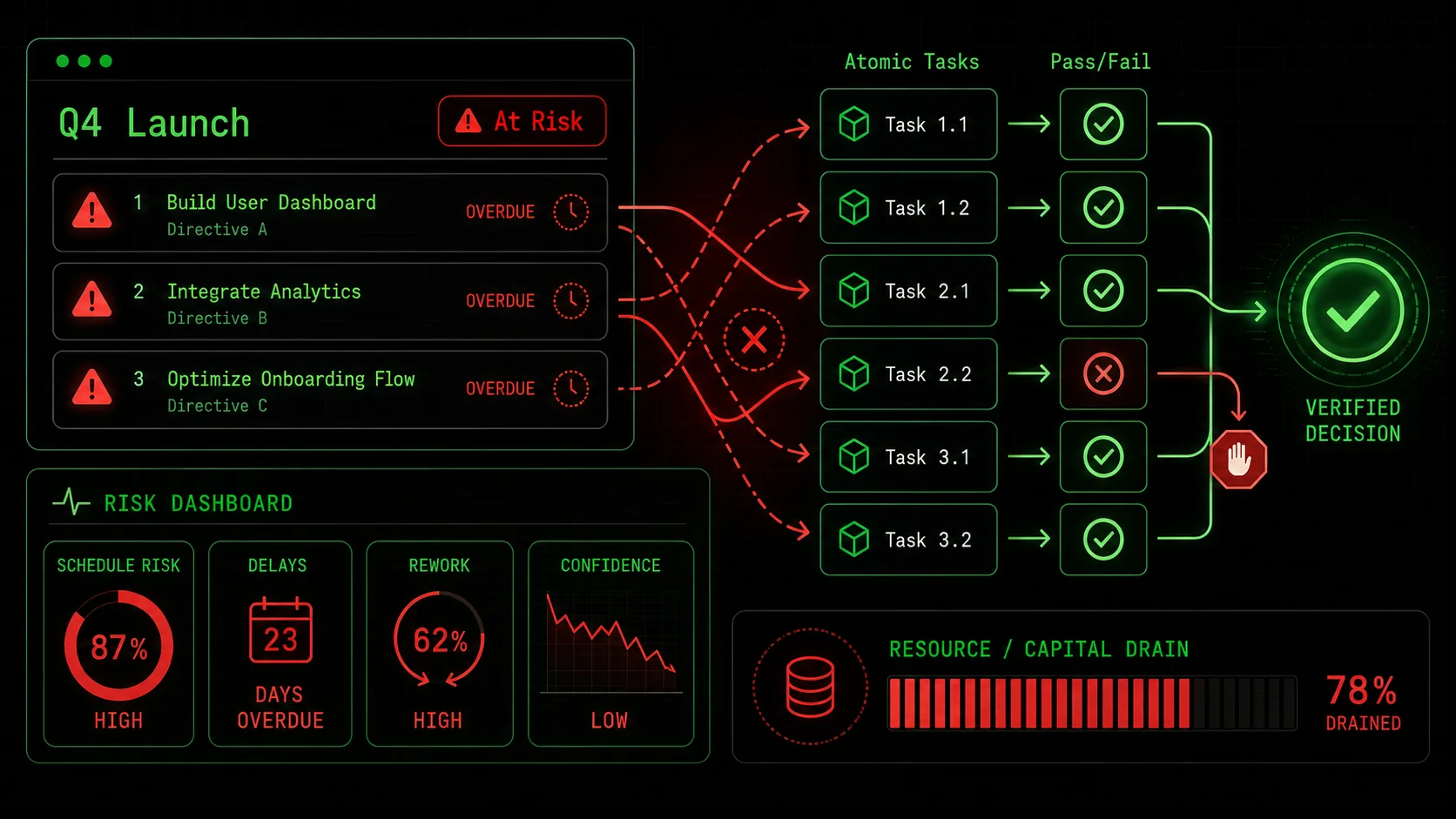
The temptation to offload strategic thinking is immense. The promise is a 10x productivity boost. But when the strategy is built on guesswork, the cost isn’t just a bad document—it’s misallocated capital, wasted time, and team disillusionment. That TechCrunch report on “strategic drift” isn’t about academic failure; it’s about real companies chasing AI-generated mirages.
Let’s break down the concrete risks.
The Illusion of Consensus An AI-generated strategy document is often so well-written that it short-circuits healthy debate. A team might see a polished, confident plan and assume the underlying reasoning is sound. This creates a false consensus. No one fought over the assumptions because the AI presented them as facts. I’ve seen this in technical planning sessions: a developer might hesitate to question a slickly presented AI architecture diagram, only to discover weeks later that a core component is incompatible with their stack. The plan looked so complete that it discouraged the necessary scrutiny. This is why using structured prompts for AI-driven product management is less about generation and more about creating a framework for interrogation. The Accountability Vacuum Who is responsible when a guessed strategy fails? You can’t blame the AI. The human who prompted it is ultimately accountable, but they were following a plan that seemed rigorous. This creates an accountability vacuum. The failure gets attributed to “the AI being wrong,” which leads to AI skepticism, or to poor execution, which demoralizes the team. Neither addresses the root cause: the strategy was never stress-tested at the task level. A strategy built from atomic tasks flips this. Each task has a clear pass/fail. If a task fails, you debug that specific task. The accountability is precise and actionable. The Resource Sinkhole This is the most direct financial risk. A guessed strategy might recommend “building a community on a new platform” or “investing in a specific ad channel.” Teams then spend months and budgets executing these directives. A study by the Project Management Institute consistently finds that a leading cause of project failure is poorly defined initial requirements and objectives—exactly what AI guesswork produces. Without atomic, testable tasks at the outset, you commit resources based on a narrative, not evidence. You might spend $50,000 on a marketing channel before a $500 atomic task—like “Run a $500 test campaign on Channel X and achieve a CPA under $Y”—could have told you it wouldn’t work. Erosion of Strategic Muscle Finally, over-reliance on strategy-as-text atrophies an organization’s own strategic thinking. Whether you use Claude Code, Cursor, or GitHub Copilot for planning, the risk is identical. Strategy is a muscle built through the hard work of defining problems, challenging assumptions, and forging logical paths. Outsourcing that to an AI that provides answers without showing its work (in a verifiable way) makes the team dumber, not smarter. The goal should be augmentation, not replacement. The AI should handle the computational heavy lifting—the data gathering, the scenario modeling, the drafting of options—within a strict framework that the human strategist defines and controls. This preserves and enhances human judgment rather than sidelining it.The common thread in all these risks is unverified abstraction. The AI operates at a high level of abstraction, and we accept its outputs without forcing them down to the concrete level where reality lives. The fix is to build a bridge between the abstract and the concrete, one atomic, verifiable task at a time.
How to Build an Unbreakable AI Strategy: The Atomic Task Method
Deconstruct grand visions into atomic tasks with binary pass/fail criteria, then let Claude Code execute and self-validate each step -- eliminating hallucinated data points and untested assumptions.

Transforming Claude Code from a guesser into a reliable strategist requires a new methodology. You stop asking for a “plan” and start building a “skill”—a self-contained workflow of atomic tasks that the AI will execute sequentially, stopping to validate each step before moving on. Here’s your step-by-step blueprint.
Step 1: Deconstruct the Grand Vision into Problem Statements
You don’t start with “Create a strategy.” You start by ruthlessly deconstructing your grand vision into a series of fundamental, answerable questions. This is the most important human-led step.Bad starting point: “Plan our expansion into the German market.” Good starting points: * “What are the top 3 customer segments for our product in Germany, and what are their primary pain points?” * “What are the regulatory hurdles for our service in Germany, and what is the estimated compliance cost?” * “Who are our direct and indirect competitors in Germany, and what is their pricing strategy?”
Each of these is a discrete problem that can be solved with research and analysis. Write them down as clear, imperative problem statements. This list becomes the backbone of your strategic “skill.” For solopreneurs juggling every role, this deconstruction is especially critical. It turns an overwhelming strategic leap into a series of manageable hops, a principle we explore in depth for solopreneur AI workflows.
Step 2: For Each Problem, Design Atomic Tasks with Binary Pass/Fail Criteria
This is the core of the method. Take your first problem statement and break it into the smallest possible tasks that, when combined, solve it. For each tiny task, you must define criteria so clear that the AI (or a human) can objectively say “pass” or “fail.” Example: Problem = “Identify top competitors in Germany.”* Atomic Task 1: “Using a web search, find and list 10 companies that offer [your product type] to the German market. Provide company name and website URL.” * Pass Criteria: List contains exactly 10 entries. Each entry has a valid company name and a working URL. * Atomic Task 2: “For each company from Task 1, visit their pricing page and document their entry-level monthly price in EUR. If no public pricing, note ‘Enterprise’.” * Pass Criteria: All 10 companies have a documented price or ‘Enterprise’ flag. * Atomic Task 3: “Analyze the collected pricing data. Calculate the average, median, and range of entry-level prices. List the 3 companies with the lowest price.” * Pass Criteria: Average, median, and range are calculated and presented. The 3 lowest-priced companies are correctly identified from the data.
Notice how each task is a single instruction. The pass/fail criteria are not subjective (“good analysis”); they are objective checks on the output’s completeness and format. Claude Code can execute each task and then check its own work against the criteria before you ever see it. If Task 2 only finds prices for 8 companies, it fails. The AI doesn’t just move on and hide the gap; it either retries or flags the issue for you.
Step 3: Implement the Loop: Execute, Validate, Iterate
Now you feed this sequence of atomic tasks to Claude Code, not as a prompt for a summary, but as a set of operational instructions. You use the Ralph Loop methodology to formalize this.This loop is what kills guesswork. An AI guessing a strategy might invent or approximate competitor names and prices. An AI running this atomic task loop must produce verifiable evidence (URLs, extracted prices) and confirm it meets your standards before it’s allowed to do any analysis. The final “strategy” is not a text document, but a report of passed tasks with their validated outputs—a data-backed foundation for decision-making.
Step 4: Synthesize Validated Outputs into Strategic Decisions
Once all your problem-specific skill loops have run and passed, you have something precious: a collection of verified facts and analyses. Now you do strategy.You bring these outputs to a human decision-making forum. “Based on the validated data, the average price point is X, with the market leader charging Y. Our cost structure allows us to compete at Z. Regulatory review task passed, indicating a 3-month timeline for compliance. Therefore, our recommended market entry price is Z, with a go-live date of Q3.”
The AI didn’t make the strategic call. It built the verified information platform upon which a sound human decision can stand. This synthesis is where human experience, intuition, and risk appetite come into play, using inputs that are as reliable as you’ve designed your atomic tasks to be. This process of moving from atomic verification to strategic synthesis is a powerful pattern you can apply across your business, which is why we’ve compiled related techniques in our central AI prompts hub.
Tools and Templates to Get Started
You can implement this manually in a Claude Code session with disciplined prompting. However, tools like the Ralph Loop Skills Generator are built specifically to formalize this process—allowing you to define skills, atomic tasks, and pass/fail criteria in a reusable template that can be run consistently.For research tasks, guide Claude to use specific, credible sources. Instead of “search the web,” prompt it to “Consult the Statista database for reports on the German tech market size” or “Review the latest annual reports from [Company X] and [Company Y].” This steers the AI toward higher-quality inputs. For analytical tasks, provide clear output formats: “Present the findings in a table with columns for Company, Price (EUR), and Pricing Model.”
Putting Atomic Strategy to Work: From Market Research to M&A
Atomic task workflows scale from competitor pricing analysis to M&A due diligence and portfolio rationalization -- using Claude Code and Cursor to verify each data point before synthesis.
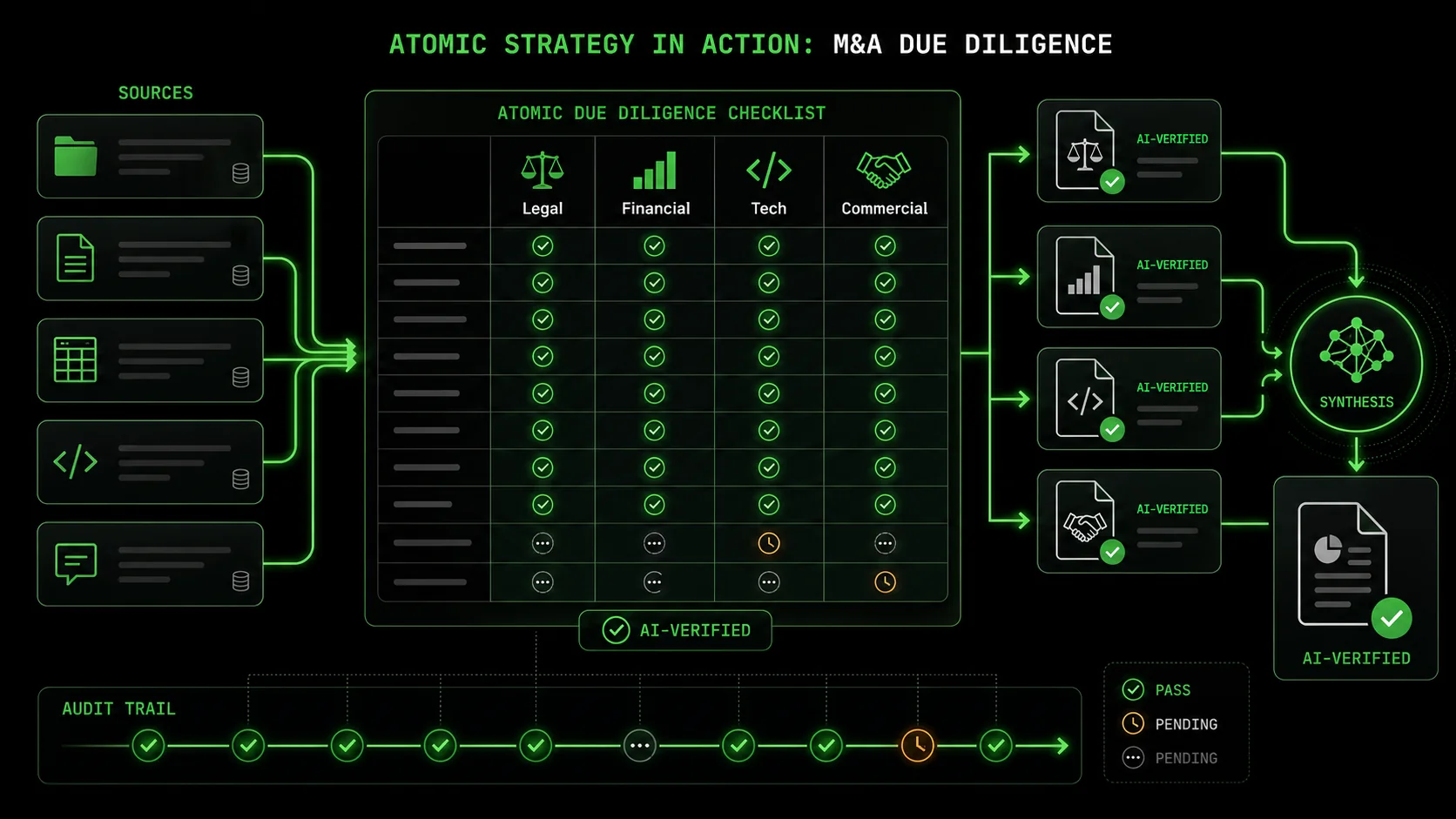
The atomic task method isn’t just for market entry. It’s a universal framework for turning any complex, high-stakes business problem into a manageable, auditable AI workflow. Let’s look at two advanced applications.
Due Diligence for Acquisitions M&A is a minefield of guesswork and assumption. An atomic strategy flips it into a verification engine. * Problem: “Assess the technology stack compatibility of Target Company.” * Atomic Tasks: 1. “From the provided data room index, identify all documents related to technology architecture and software licenses.” 2. “Extract the primary programming languages, frameworks, and third-party SaaS tools listed in those documents into a standardized table.” 3. “Compare each item in the table against our company’s approved technology stack and security standards. Flag each item as ‘Compatible,’ ‘Incompatible,’ or ‘Requires Review.’” 4. “For items flagged ‘Incompatible,’ estimate the engineering cost and timeline for migration or replacement based on our internal cost database.”Each task has pass/fail criteria based on document coverage, extraction completeness, and comparison logic. The output isn’t a paragraph saying “there might be some integration challenges.” It’s a validated spreadsheet with line-item risks and quantified estimates. This turns a nebulous risk into a concrete budget line.
Product Portfolio Rationalization Deciding which products to grow, maintain, or sunset is emotionally and politically charged. Atomic tasks inject data-driven objectivity. * Problem: “Rank our five legacy products by strategic value and maintenance burden.” * Atomic Tasks: 1. “Connect to our internal analytics database (via provided schema). Pull total revenue, customer count, and support ticket volume for each product over the last 12 months.” 2. “Access the code repository. For each product, calculate the lines of code, number of active contributors in the last 6 months, and frequency of commits.” 3. “Using a weighted scoring model (revenue 40%, customers 30%, support burden 15%, code activity 15%), calculate a ‘Strategic Value Score’ for each product.” 4. “Present results in a ranked table, including a ‘Recommendation’ column (Scale, Maintain, Sunset) based on score thresholds we define.”The AI isn’t deciding the fate of products. It’s executing the tedious, multi-source data gathering and consistent calculation that humans often do inconsistently. The pass/fail criteria ensure no product is missed and the math is correct. The final ranked table becomes the unbiased starting point for a leadership debate.
The Key to Advanced Applications: The more complex the scenario, the more valuable the “self-validating loop” becomes. In M&A or portfolio analysis, a single piece of missed or misinterpreted data can lead to a catastrophic decision. The atomic task method’s requirement for verification at each step acts as a series of circuit breakers, preventing a cascade of errors. It forces the AI—and by extension, your process—to slow down and get each piece right before synthesizing the whole. This disciplined, iterative approach is what separates reliable AI augmentation from dangerous automation.Got Questions About AI Strategy? We've Got Answers
Common questions about using Anthropic's Claude, OpenAI's GPT-4, GitHub Copilot, and Cursor for atomic, criteria-driven strategic planning workflows.
How long does it take to set up an atomic task strategy? The initial setup for your first strategic “skill” might take 30-60 minutes—significantly longer than typing a one-sentence prompt. This time is spent thinking, deconstructing the problem, and defining precise tasks and criteria. This is the critical investment. Once built, these skills become reusable templates. Your second and third strategic analyses will be much faster, and the quality will be consistently high because the verification logic is baked in. It’s front-loaded work for compounded, reliable returns. What if the AI can't find the data to pass a task? This is a feature, not a bug. If an atomic task like “Find the market share percentage for Company X in Germany” fails because the data genuinely doesn’t exist publicly, the AI reports the failure. This is invaluable information. In a traditional guessed strategy, the AI might hallucinate a plausible number (e.g., “15%”). In the atomic method, you get a clear signal: “Task Failed: Could not locate verified market share data from specified sources.” This tells you that piece of intelligence is unknown, which should influence your decision-making risk profile. You now know what you don’t know. Can I use this for real-time, fast-paced strategic decisions? The atomic task method is ideal for complex, consequential decisions where the cost of error is high—market entry, M&A, major investment. For real-time, tactical decisions (e.g., “How should we respond to this social media crisis?”), a more fluid, direct prompt might be appropriate. However, you can still apply the core principle: break the crisis response into verifiable components. “Task 1: Summarize the key complaints from the last 50 tweets. Pass Criteria: Summary covers all major themes.” This adds rigor even to fast-moving situations. What's the biggest mistake people make when starting with this method? The most common mistake is making the atomic tasks too large or the pass/fail criteria too vague. “Analyze the competitor’s website and write a summary” is not atomic. “List the five main navigation menu items on competitor.com” is atomic. “Pass if the summary is good” is useless. “Pass if the list contains exactly 5 items and each is a direct quote from the page” is usable. Start smaller and more mechanical than you think you need to. You can always chain more tiny tasks together. It’s much harder to retroactively add verification to a large, fuzzy output.Ready to replace strategic guesswork with verified execution?
Ralph Loop Skills Generator turns your most complex business challenges into sequences of atomic, verifiable tasks. Anthropic’s Claude Code then executes them iteratively, checking its own work at every step until everything passes. Stop wondering if your AI’s plan is just a good story. Start building strategies with the integrity of code. Generate your first strategic skill today.Related guides
- Why Your AI’s Business Plan is Failing the First Investor Meeting -- when Claude and GPT-4 produce plans that crumble under scrutiny
- AI Business Plan Missing the Mark: How to Fix It -- actionable fixes for AI-generated business strategies
- AI Prompts for Product Managers -- 30+ prompts for PRDs, roadmaps, and user stories with Claude Code and Cursor
- The AI Project Manager Fallacy -- why OpenAI’s GPT-4 and Anthropic’s Claude cannot replace human planning judgment
Other Doved Studio projects
Related tools from the same studio you might find useful:
- Glean: Turn scrolling time into a daily action plan. Capture, process, execute.
- Popout: Create your portfolio in minutes with a single shareable page.
- Larpable: Spot fake founders, guru grifts, and performance entrepreneurship.
- Doved Studio: Studio indie derrière cette app et une dizaine d'autres outils.
ralph
Building tools for better AI outputs. Ralphable helps you generate structured skills that make Claude iterate until every task passes.