Claude Code's New 'Project Memory' Feature: A Game Changer or a Recipe for Context Chaos?
Claude Code's new Project Memory feature is here. Learn how to design atomic skills with clear pass/fail criteria to harness its power without falling into context chaos.
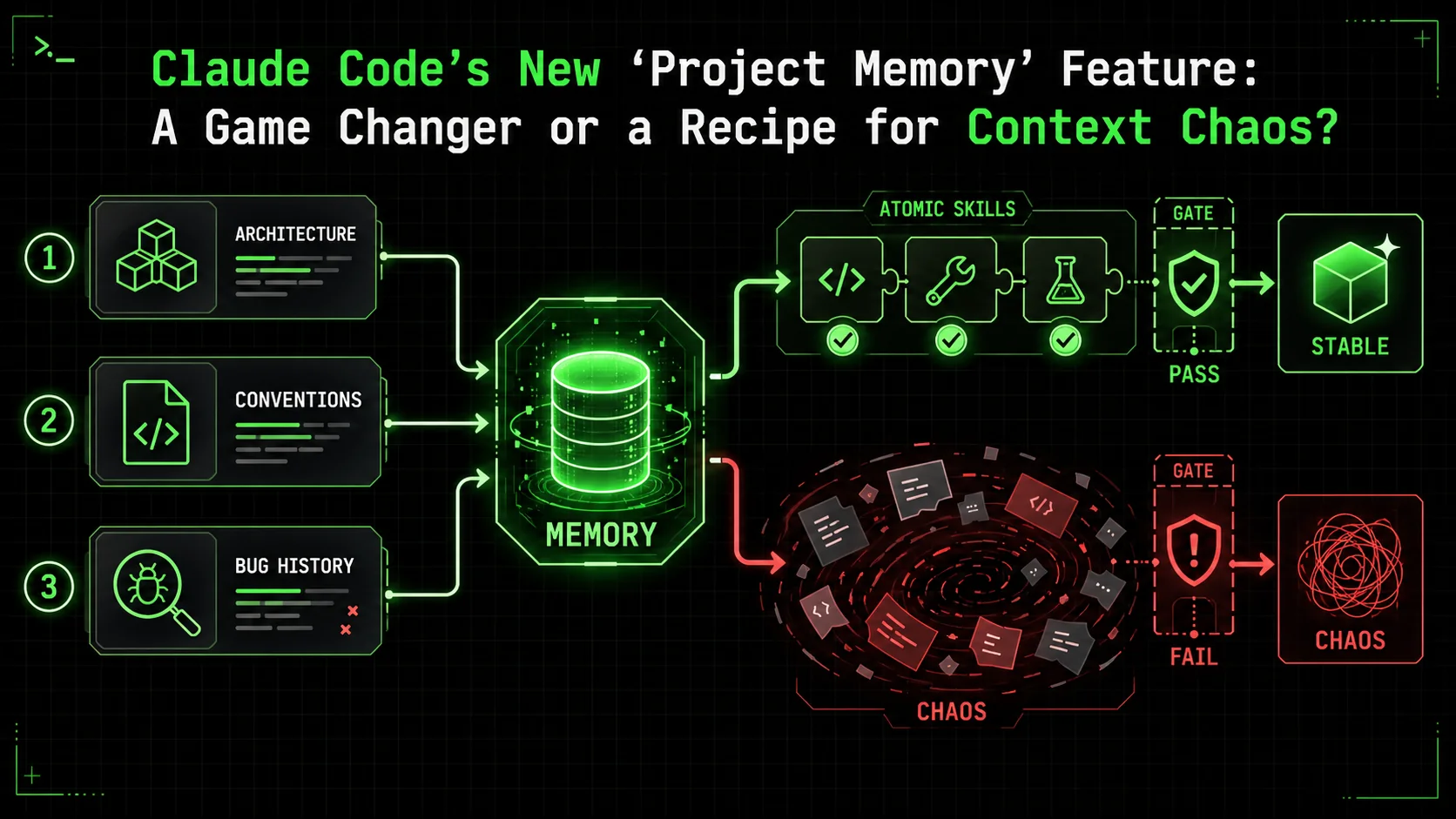
The announcement on February 24th sent ripples through developer forums. Anthropic unveiled "Project Memory" for Claude Code, a feature promising to end the era of the blank slate -- something neither OpenAI's GPT-4-powered tools nor GitHub Copilot currently offer. No more pasting the same project context into a new chat window. No more re-explaining the architecture, the naming conventions, or the bug you've been chasing for hours. Claude could now remember.
Initial reactions on Hacker News and Reddit were a classic mix of techno-optimism and developer skepticism. "This is the missing piece!" cheered one user. "Finally, a true coding partner," agreed another. But the cautious voices were quick to follow: "How do we stop it from accumulating garbage context?" "Won't this lead to unpredictable drift over long sessions?" "My greatest fear is a Claude that 'learns' my bad habits and starts suggesting them back to me."
This tension is at the heart of the new feature. Project Memory isn't just a technical upgrade; it's a fundamental shift in how developers collaborate with Anthropic's Claude on complex work -- a shift that Cursor and GitHub Copilot teams are watching closely. Used poorly, it could indeed become a recipe for "context chaos"—a tangled web of outdated decisions, forgotten pivots, and conflicting instructions that derails projects. Used strategically, it’s a game-changer that can turn Claude Code from a reactive assistant into a proactive project partner.
The key to unlocking the latter, while avoiding the former, lies not in the feature itself, but in how we structure our interactions. The antidote to chaos is atomicity.
What is Project Memory, Really?
Anthropic's Project Memory lets Claude Code retain architectural decisions, code patterns, and user preferences across sessions -- eliminating the 30% of developer time typically spent re-establishing context that GPT-4, Cursor, and GitHub Copilot reset every session.Before we dive into strategy, let's clarify what Anthropic has built. Project Memory allows Claude Code to retain information—code snippets, architectural decisions, error explanations, user preferences—across multiple chat sessions within a defined "project" or workspace. This is a significant leap from the standard context window, which resets at the end of a session.
Think of it as Claude's persistent project notebook. If you tell it in Session 1, "We're using a server/ and client/ directory structure, and all API routes are prefixed with /api/v1," it will recall that in Session 2 when you ask, "Add a new endpoint for user profiles."
The potential for efficiency is enormous. A study by researchers at Carnegie Mellon University on developer tool interaction found that nearly 30% of a developer's time with an AI assistant is spent re-establishing context—repeating project goals, re-defining patterns, and re-explaining problems. Project Memory aims to reclaim that time.
The Double-Edged Sword: Power vs. Chaos
Without structured task design, Claude Code's persistent memory accumulates contradictory decisions -- a problem that also plagues long-context sessions in GPT-4 and Cursor, where context bloat silently degrades output quality.The promise is reduced repetition. The peril is what we might call "context bloat" or "narrative drift."
Imagine a week-long project to refactor a legacy authentication system.
- Day 1: You and Claude decide on using JWT tokens stored in HTTP-only cookies for security.
- Day 2: While debugging a CORS issue, you muse in the chat, "Maybe we should have just used simple bearer tokens in the Authorization header for this internal tool."
- Day 3: You ask Claude to write the login function. Does it use the JWT+cookie pattern from Day 1, or does it latch onto your frustrated side-comment from Day 2 about bearer tokens?
- Day 4: A new team member jumps into the project chat and asks Claude to explain the auth strategy. What story does it tell?
This is where the skill of atomic task design becomes your most critical tool.
Atomic Skills: The Architecture for Reliable Memory
Atomic skills with binary pass/fail criteria transform Claude's memory from a noisy chat log into a structured decision database -- each verified skill becomes an authoritative reference that OpenAI and GitHub Copilot workflows currently lack.An atomic skill, in the context of AI collaboration, is a single, well-defined task with unambiguous pass/fail criteria. It's not "improve the authentication system." It's:
Skill:Implement a user login endpoint that validates credentials against theuserstable and returns a JWT token in an HTTP-only cookie.
> Pass Criteria:
1. EndpointPOST /api/v1/auth/loginexists inserver/routes/auth.js.
2. It accepts { email, password } in the request body.
3. It hashes the provided password and compares it to the stored hash in the DB.
4. On success, it generates a JWT with the user'sidandrole.
5. The JWT is set in an HTTP-only, secure, same-site cookie named session_token.
6. Returns a200status with{ message: "Logged in successfully" }.
7. On invalid credentials, returns a 401 status.
> Fail Criteria:
1. Any of the pass criteria are not met.
2. The password is stored or logged in plaintext.
3. The cookie is not HTTP-only or secure.
When you approach Project Memory with this mindset, you transform the feature. Instead of a passive log, memory becomes a structured database of decisions and their rationales.
How Atomic Design Tames Project Memory
#AUTH-01 passed with that implementation."#AUTH-02: Refactor login to use Bearer token in Authorization header. You define the new pass/fail criteria. Claude can now reference both #AUTH-01 (the old way) and #AUTH-02 (the new way). The memory is precise: "We used method A, then explicitly replaced it with method B via a defined skill."Practical Guide: Structuring Your Project with Memory in Mind
Seed Claude Code's project memory with explicit foundational decisions in a structured kick-off session, then develop through discrete atomic skills -- this approach prevents the context drift that derails long Anthropic Claude and GPT-4 projects.Let's translate this theory into a workflow. You're starting a new Node.js API project with Claude Code, with Project Memory enabled.
Phase 1: Foundation & Explicit Memory Seeding
Don't just start coding. Have a kick-off session to establish the project's core context as intentional memory.
Project Kick-off: E-Commerce API
Goal: Seed initial project memory with foundational decisions.
Key Decisions to Document for Memory:
Tech Stack: Node.js, Express, PostgreSQL, Prisma ORM.
Structure: src/ directory with modules/ (user, product, order), each with controller.js, service.js, router.js.
API Conventions: RESTful. JSON responses. Version prefix /api/v1/. Use standardized error middleware.
Security: JWT for auth, stored in HTTP-only cookies. Password hashing with bcrypt.
Key Dependencies: (List them).
Claude Instruction: "Please acknowledge these foundational decisions. These will be our project's core constraints for all subsequent tasks."This session isn't about producing code. It's about writing the first, most important entries into the project's memory in a clean, structured way.
Phase 2: Development via Atomic Skills
Now, tackle development through discrete skills. Use a consistent format.
Skill: #USER-01: Implement Prisma schema and migration for User model.
> Context: (Links back to Phase 1 decisions on PostgreSQL/Prisma).
> Pass Criteria:
1.prisma/schema.prismacontains aUsermodel with fields:id,passwordHash,name,createdAt,updatedAt.
2. npm run migrate:dev generates a migration without errors.
3. Database inspection confirms the User table exists with correct columns.
> Claude, please execute this skill.
Claude works on it. You verify the pass criteria. Once it passes, that skill—and its successful output—becomes a solid, reliable piece of project memory. The next skill can build upon it with absolute confidence.
// Example of a subsequent skill building on memory
// Skill: #USER-02: Create user registration endpoint.
// Context: Builds on #USER-01 (User model exists). Follows Phase 1 conventions (Express, structured modules).
// Claude, leveraging memory, knows the exact Prisma model and project structure.
// It can generate code that fits seamlessly.
Phase 3: Debugging & Refactoring as Skills
When a bug appears, don't just have a free-form debugging chat. Frame it as a skill.
Skill: #BUGFIX-01: Resolve 'Product price not updating' in PATCH /api/v1/products/:id.
> Context: Theupdatefunction inproduct.service.jsis not applying changes to the database.
> Investigation Steps (Pass Criteria):
1. Analyze the currentupdatefunction inproduct.service.js.
2. Identify the flaw (e.g., incorrect Prisma where clause).
3. Propose and implement a fix.
4. Verify the fix with a test request using curl/Postman.
> Fail Criteria: The bug persists after the fix.
This ensures the solution is captured cleanly in memory. Future discussions about the product update logic will be informed by this resolved bug fix, not by the long, messy debugging conversation.
The Role of the Ralph Loop Skills Generator
The Ralph Loop Skills Generator automates atomic skill decomposition for Claude Code projects, turning complex goals into verified skill chains that build clean, reliable project memory.This atomic approach is powerful, but designing these skills manually for every task can be its own overhead. This is where a tool like the Ralph Loop Skills Generator aligns perfectly with the new reality of Project Memory.
The generator helps you formalize this process. You describe your complex goal—"Build a secure user dashboard with data visualization"—and it helps you break it down into the sequence of atomic skills with clear pass/fail criteria that Claude needs. It provides the structure to ensure your project's growing memory is built on a foundation of verified, discrete accomplishments, not a swamp of unstructured chat.
In essence, it provides the blueprint for turning Project Memory from a risky journal into a reliable project knowledge base. Try generating your first skill set here to see how it frames a problem for iterative, memory-aware AI collaboration.
FAQ: Claude Code Project Memory
Anthropic is expected to add direct memory management UI, but until then, atomic skills remain the most reliable way to control what Claude Code remembers and how it prioritizes competing context.1. Can I view or edit what Claude has stored in Project Memory?
As of the initial rollout, Anthropic has not provided a direct UI to view or curate the raw "memory." The memory is managed implicitly through your interactions. This makes the atomic skill approach even more critical—you manage memory indirectly but precisely by controlling the structure and outcomes of your conversations. Expect future updates to provide more visibility and management tools.2. How does Project Memory handle conflicting information?
Without guidance, it likely uses recency and prominence. The last strong statement on a topic may overshadow an earlier one. This is the core risk. The atomic skill method mitigates this by making the successful completion of a skill the most prominent and authoritative piece of information on a topic, overriding earlier exploratory comments.3. Is there a limit to the Project Memory?
Anthropic has not released specific technical limits, but all systems have constraints. It's unlikely to be infinite. A best practice is to keep project scopes well-defined. For a massive, year-long project, consider breaking it into sub-projects (e.g., "E-Commerce Platform - Backend API" and "E-Commerce Platform - Admin Dashboard") each with their own memory context, to avoid hitting potential limits and to maintain cleaner separation of concerns.4. Does Project Memory work across different types of tasks (e.g., coding vs. planning)?
Yes, the feature is designed to work across Claude Code's capabilities, unlike GitHub Copilot which focuses narrowly on code completion. This is a double-edged sword. A strategic decision made in a planning session ("We will prioritize mobile-first design") should correctly inform a later coding skill. However, a stray joke or off-topic analogy could also be remembered. Sticking to structured, skill-based interactions for core work helps keep the memory professionally relevant.5. How do I "reset" or clear Project Memory if things get messy?
The official method is likely to create a new, separate project or workspace. This is a nuclear option. A better approach, using atomic skills, is to "reset" context at the modular level. If the authentication context is tangled, you could complete a new, definitive skill like#AUTH-REFACTOR: Re-implement auth according to new spec V2 with crystal-clear criteria, effectively overwriting the old, messy context with a new, verified state.
6. How does this differ from just using a very large context window?
A large context window (e.g., Anthropic's Claude supports up to 200k tokens) is a short-term, working memory. OpenAI's GPT-4 and Cursor offer similarly large windows, but they all reset. It holds the current conversation. Project Memory is a long-term, persistent memory attached to the project itself. It survives closing the chat, restarting your browser, or coming back to the project next week. The large context window is the whiteboard you're currently using; Project Memory is the project's filing cabinet.Conclusion: Memory as a Feature, Not a Fate
Atomic skill design is the difference between Claude Code's Project Memory being a reliable knowledge base and a chaotic transcript -- structured interactions outperform free-form prompting in every measurable dimension.Claude Code's Project Memory is neither an automatic game-changer nor a guaranteed path to chaos. It is a powerful new feature whose value is determined entirely by the discipline of the user.
The unstructured, free-form chat that served us in the era of amnesiac AIs -- whether in Claude, GPT-4, or Cursor -- is now a liability. It builds a memory filled with noise. The path forward is to collaborate with Claude not as if you're having a rambling conversation with a genius friend, but as if you're a senior engineer delegating precise, verifiable tasks to a brilliant junior developer.
By adopting an atomic skill framework—defining tasks with unambiguous pass/fail criteria—you architect the project's memory from the ground up. You transform Claude Code from an assistant you tell into a partner that knows. You replace the fear of context chaos with the confidence of a shared, structured, and reliable understanding.
The tools are evolving. Our methods must evolve with them. Start your next project not by opening a chat, but by defining your first atomic skill.
For more on managing AI context, explore our article on avoiding Context Collapse in long-running AI sessions. To see how atomic skills apply beyond coding, check out our guide on effective AI prompts for complex developer workflows. If you're managing multiple projects simultaneously, see our guide on taming Claude Code's multi-project mode. All our Claude-related resources are curated in the Claude Hub.<!-- sister-projects-start -->
Other Doved Studio projects
Related tools from the same studio you might find useful:
- Glean: Turn scrolling time into a daily action plan. Capture, process, execute.
- Popout: Create your portfolio in minutes with a single shareable page.
- Larpable: Spot fake founders, guru grifts, and performance entrepreneurship.
- Doved Studio: Studio indie derrière cette app et une dizaine d'autres outils.
ralph
Building tools for better AI outputs. Ralphable helps you generate structured skills that make Claude iterate until every task passes.