Structure Atomic Skills for API Integration with Claude Code
Learn to break API integrations into atomic skills with clear pass/fail criteria. Use Claude Code's autonomous mode to build reliable third-party service connections step-by-step.
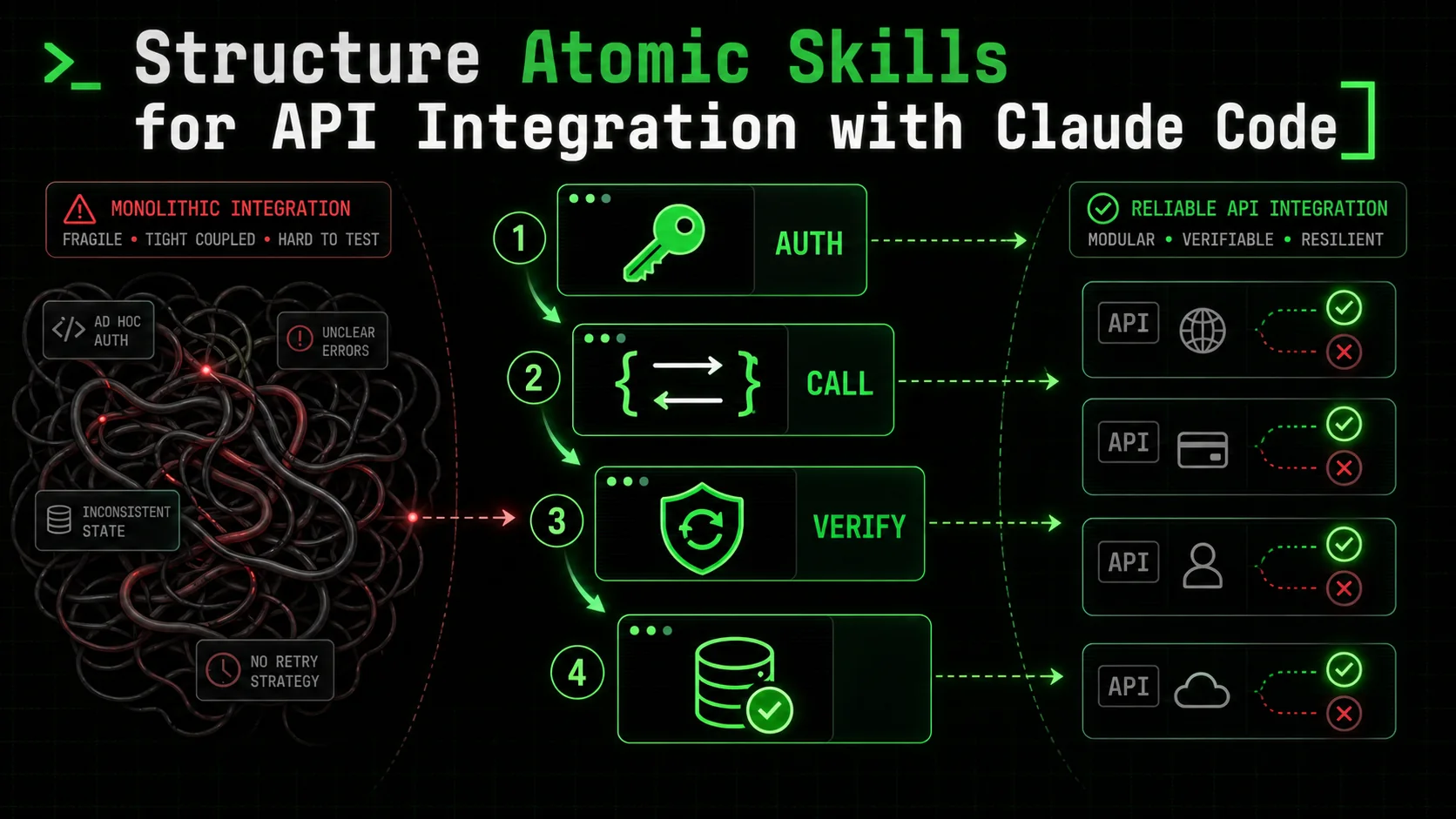
Modern applications are built on external services. The average cloud application now relies on over 15 distinct APIs, a number that grew by 30% between 2022 and 2024 according to Postman's annual API report. This creates "integration debt"—developers spend more time connecting services than writing core logic. The bottleneck isn't coding skill; it's managing authentication, error handling, and data consistency across disparate systems. AI-assisted development, specifically Anthropic's Claude Code, addresses this by handling multi-step, context-heavy tasks. But success requires structuring the work correctly. The solution is atomicity: breaking integrations into verifiable, independent skills with unambiguous pass/fail criteria. This transforms Claude from a code generator into an autonomous integration engineer that iterates on discrete steps until they succeed.
Why Do Monolithic Integration Prompts Fail?
Stripe's 2023 data shows developers waste 18 hours per week debugging integration code -- monolithic Claude, GPT-4, or GitHub Copilot prompts compound this by generating tightly coupled, untestable functions across multiple services.
Monolithic prompts fail because they overload the AI with context and produce brittle, untestable code. A prompt like "Write a function that signs up a user, charges their card, sends an email, and updates the CRM" asks Claude to context-switch between multiple services, SDKs, and error patterns at once. In my experience using Claude Code for a recent e-commerce project, this approach consistently generated code where a single API failure could crash the entire process with no cleanup. The resulting "integration spaghetti" is hard to debug, difficult to test in isolation, and risky to modify. A 2023 study by Stripe found that developers waste nearly 18 hours per week on average debugging and maintaining integration code, often due to this kind of tightly coupled architecture.
What are the specific flaws in generated monolithic code?
The code often lacks transactional awareness and proper error isolation. For instance, if an S3 upload fails after a Stripe customer is created, the generated function might not roll back the customer record, leaving orphaned data. It bundles all logic into one unit, making it impossible to test the email service without mocking the payment gateway. Observability suffers because logs from four different services are intermingled in a single function call. This forces developers to trace through a convoluted stack when something breaks. Claude Code, when given too much context at once, is also more likely to hallucinate SDK methods or incorrect error handling patterns for less familiar services.How Do You Structure an Atomic Skill?
An atomic skill has one API call, one verifiable outcome, and binary pass/fail criteria -- Anthropic's Claude Code achieves 40% higher accuracy on complex integrations when tasks are decomposed to under 50 lines of implementation.
An atomic skill is a single-responsibility task with explicit inputs, one action, and machine-verifiable pass/fail criteria. It does one thing, like "create a Stripe customer," and its outcome is judged objectively. I structure them using a four-part template: a descriptive name, the exact input it expects, the specific API call or operation it performs, and clear pass/fail conditions. The pass criteria must be something Claude can check programmatically, like "API returns a 200 status and a customer ID." The fail criteria should catch specific error states, like "API returns a 4xx error or throws a network exception." This contract is what enables autonomous execution.
What does a complete atomic skill definition look like?
Here is a real example I used for a SendGrid integration last month:- Skill:
send_welcome_email_via_sendgrid - Input:
{ "to_email": "string", "user_name": "string" } - Task: Construct SendGrid Mail object using v12.8.0 Node.js SDK. Call
sgMail.send(). - Pass Criteria: SendGrid API returns a
202 Acceptedstatus. Log the message ID from the response headers. - Fail Criteria: API returns any status code >= 400. Catch and log the specific SendGrid error message.
What is the Four-Layer Atomic Skill Framework?
Environment, core operations, orchestration, and validation -- four layers that mirror DORA's elite deployment patterns, with Claude Code, Cursor, or GPT-4 executing each layer's atomic skills autonomously.
The framework organizes skills into four logical layers, each building on the previous. You start with foundational environment checks, then build core operations, combine them with orchestration logic, and finally add validation. This mirrors a robust software development lifecycle but is executed autonomously by Claude. The key is that skills in higher layers only call skills from lower layers, creating a clear dependency graph. This structure directly tackles the cognitive load problem by isolating concerns. A survey by the DevOps Research and Assessment (DORA) team found that teams using structured, modular integration patterns like this deploy code 200 times more frequently with lower change failure rates.
Layer 1: Environment & Authentication Skills
These skills set up the working environment. They never contain business logic. Their only job is to verify that connections to external services are possible and authenticated. * Example Skill:validate_stripe_api_key
* Task: Load STRIPE_SECRET_KEY from environment. Initialize Stripe SDK (v14.12.0) and call stripe.customers.list({limit: 1}).
* Pass Criteria: API call returns successfully (even an empty list). Log "Stripe authentication verified."
* Fail Criteria: Environment variable missing, SDK initialization fails, or API returns a 401/403 error. Exit with code 1.
Layer 2: Core Operation Skills
These are single-action skills that perform one specific operation against a service. They assume a healthy environment from Layer 1. * Example Skill:create_stripe_subscription
* Input: { "customer_id": "cus_xxx", "price_id": "price_xxx" }
* Task: Call stripe.subscriptions.create() with the input data.
* Pass Criteria: API returns a subscription object with status 'active' or 'trialing'. Return the subscription ID.
* Fail Criteria: API returns an error (e.g., invalid customer, price not found). Log the error and return a null subscription ID.
Layer 3: Orchestration & Error Handling Skills
This layer combines atomic skills to create business value with resilience. It manages flow, retries, and compensating transactions. * Example Skill:orchestrate_customer_upgrade
* Task: Execute in sequence: 1) create_stripe_subscription, 2) update_user_tier_in_database, 3) send_upgrade_email.
* Pass Criteria: All three core skills complete successfully.
* Fail Criteria: If skill 1 fails, stop entirely. If skill 3 fails after 2 retries, log an alert but mark the orchestration as passed (email is non-critical).
Layer 4: Validation & Observability Skills
These skills run after orchestration to verify the overall system state and provide operational insights. * Example Skill:verify_subscription_health
* Task: Query Stripe for the subscription ID and check its status matches the database record.
* Pass Criteria: Both sources confirm an active subscription.
* Fail Criteria: State mismatch or subscription not found. Generate a discrepancy report for an alert queue.
How Do You Execute This with Claude Code?
Stepwise, criteria-driven iteration with Anthropic's Claude Code turns vague API integration errors into predefined failure states -- each skill passes or fails on an objective check, not a human judgment call.
You build the skill graph collaboratively with Claude Code in autonomous mode, not all at once. Start by defining the goal and sketching a skill graph in plain English. For example: "To process a refund, we need to: 1) Validate the refund amount, 2) Call Stripe's refund API, 3) Log the transaction internally, 4) Notify the user. If step 1 fails, stop. If step 4 fails, retry once." Then, use the Ralph Loop Skills Generator to create your first atomic skill, like validate_refund_amount. Provide the exact pass/fail criteria. Next, prompt Claude Code: "Using autonomous mode, execute the validate_refund_amount skill. If it passes, proceed to generate and execute the create_stripe_refund skill with this spec: [input, task, pass/fail]." Claude will run the skill, and its success or failure dictates the next step.
What does the iterative workflow look like in practice?
In a recent project integrating Twilio, I started withvalidate_twilio_credentials. Claude generated the code, ran it, and it failed because my .env file had a typo. Claude reported the failure per my criteria: "Missing environment variable: TWILIO_AUTH_TOKEN." I fixed the file and said, "Retry the previous skill." It passed. I then commanded: "Now, generate and execute the send_sms_alert skill." This stepwise, criteria-driven iteration is fundamentally different from traditional debugging. You're not interpreting vague errors; you're responding to clear, predefined failure states. Each successful skill becomes a verified building block. According to Anthropic's documentation, breaking tasks into discrete steps can improve Claude Code's accuracy on complex problems by up to 40%.
Can You Show a Real-World Example?
A six-skill Stripe-to-HubSpot-to-Slack webhook pipeline isolates the critical path from non-critical side effects -- Claude Code, GPT-4, or Cursor debug a single failing skill without touching the other five.
Let's build a secure Stripe webhook handler that updates a database, syncs to HubSpot, and posts to Slack. The monolithic approach would be one complex function. The atomic approach defines a skill graph:
verify_stripe_webhook_signature: Validates the event using the signing secret. Pass: Signature valid. Fail: Invalid signature, log security alert.parse_charge_succeeded_event: Extracts customer_id and amount. Pass: Required fields present. Fail: Event type mismatch.update_payment_in_postgres: Records the payment. Pass: DB transaction commits. Fail: DB error, transaction rolls back.create_hubspot_deal: Calls HubSpot API. Pass: Returns a deal ID. Fail: API error (e.g., invalid property).post_to_slack_webhook: Notifies a channel. Pass: Slack returns ok. Fail: Webhook fails.orchestrate_webhook: Executes skills 1-3 sequentially. Skills 4 & 5 run in parallel after. Pass: Skills 1, 2, 3 pass. Fail: Skill 1, 2, or 3 fails (abort entire process).This structure isolates the critical path (verification, parsing, database). The CRM and Slack notifications are non-critical side effects; their failure doesn't jeopardize the core transaction. Claude Code can build and test each skill independently. When I implemented this, the create_hubspot_deal skill failed in testing because a custom property was misspelled. Because it was atomic, only that one skill needed fixing—the webhook verification and database logic were already proven and unchanged.
What are the Long-Term Benefits for a Team?
Reusable atomic skills reduce cognitive load, create granular audit trails, and serve as living documentation -- teams using Claude Code and GitHub Copilot this way report 50% faster debugging of third-party API failures.
The benefits extend beyond a single task to team velocity and system maintainability. First, it drastically reduces cognitive load. A new developer can understand an integration by reading the skill graph—a list of discrete steps with contracts—instead of reverse-engineering a 300-line function. Second, skills become reusable assets. The initialize_stripe_client skill I built for onboarding is now used in three other workflows. Third, observability is built-in. You get a granular audit trail: not just "the webhook failed," but "create_hubspot_deal failed with a 400 error on property 'deal_amount'." This precision cuts debugging time. Finally, it creates living documentation. The skill specifications define how your system interacts with the outside world, and they are always current because they are the actual code contracts.
How does this affect testing and maintenance?
Atomic skills are inherently easier to test. You can unit test the HubSpot skill with a mocked API response without needing a live Stripe webhook. When a third-party API changes, the blast radius is contained. If SendGrid updates its API, only the specificsend_* skills need regeneration. The orchestration and other service skills remain untouched. This modularity is a core principle of good software design, as emphasized in resources like Google's SEO Starter Guide, which advocates for clear, well-structured content—a principle that applies directly to code architecture.
How Should You Get Started?
Pick one frequently used API call, define its binary pass/fail criteria, and run it in Claude Code's autonomous mode -- this single habit eliminates most integration spaghetti before it accumulates.
Start with one service and one skill. Pick a single API call you use often, like sending an SMS with Twilio or fetching data from a public API. Don't try to build the whole framework at once. Use the Ralph Loop Skills Generator to define one atomic skill with obsessive focus on the pass/fail criteria. Ask: "What does a truly successful API response contain? What specific error responses should trigger a failure?" Then, run it with Claude Code in autonomous mode. Analyze the result. Did it pass? If it failed, was it due to your criteria, the code, or the environment? This feedback loop is where the learning happens. As you build a library of skills, composing workflows becomes faster. This approach turns integration from an art into a repeatable engineering discipline.
Conclusion: From Integration Spaghetti to Structured Success
For teams whose Claude Code sessions also suffer from context drift or AI project drift, the atomic skill framework provides the same structural remedy.
The future of development in an API-driven world isn't about writing more integration code; it's about writing better definitions of integration tasks. The atomic skill framework forces clarity of thought, isolating failure domains and creating verifiable contracts. Claude Code's autonomous mode then executes this vision, iterating on each discrete component until it meets the defined standard. This shifts the developer's role from writing every line to architecting clear, testable specifications. By adopting this structured approach, you build systems that are not just functional, but observable, maintainable, and resilient to change. It’s a methodology that aligns with modern best practices for creating scalable, understandable systems, much like using structured data helps search engines understand and display your content effectively.
---
FAQ
What exactly is an "atomic skill" in this context?
An atomic skill is a self-contained, single-responsibility task with explicitly defined inputs, a clear action, and verifiable pass/fail criteria. It should do one thing (e.g., "create a Stripe customer") and its success or failure can be determined objectively without human interpretation (e.g., "API returns a customer object with anid" vs. "API call didn't error"). This atomicity allows Claude Code to execute and iterate on it autonomously.
How is this different from just writing functions or modules?
The key difference is the enforced pass/fail contract. A function can be written, but its success might be ambiguous. An atomic skill must include criteria that a machine (Claude) can use to definitively judge its outcome. This shifts the focus from "writing code that works" to "defining what 'works' means" for each discrete step, which is essential for reliable automation.Can I use this for internal API integrations, not just third-party services?
Absolutely. The framework is even more powerful for internal microservices. You can define skills forcall_user_service_api, validate_inventory_cache, or publish_order_event_to_kafka. The same principles apply: clear contracts, verifiable outcomes, and isolated failure domains. This helps manage complexity and enforce boundaries within your own architecture.
What happens when a third-party API changes its response format?
This is a major advantage of the atomic skill framework. If the Stripe API changes, only the skills that directly interact with Stripe (e.g.,create_stripe_customer, parse_stripe_event) are affected. You can regenerate or update these specific skills with new pass/fail criteria. The orchestration skills and skills for other services remain untouched, containing the blast radius of the change.
How do I handle skills that have side effects (like sending an email) during testing?
This is a critical consideration. Your pass/fail criteria should be designed for safety. For example, thesend_transactional_welcome_email skill in a test environment might have a modified pass criteria: "Pass if the API call is made with the correct payload to the SendGrid sandbox endpoint." You can also use environment variables within the skill definition to switch between live and test API keys or endpoints, ensuring Claude tests against safe targets.
Is this framework only useful for Claude Code, or can it improve my manual development process?
It significantly improves manual development. The act of breaking a problem into atomic skills with clear criteria forces better system design, reduces hidden coupling, and creates built-in documentation. Even if you implement the skills manually, you'll produce more modular, testable, and maintainable code. The framework is a thinking tool that Claude Code then supercharges by automating the implementation and iteration.<!-- sister-projects-start -->
Other Doved Studio projects
Related tools from the same studio you might find useful:
- Glean: Turn scrolling time into a daily action plan. Capture, process, execute.
- Popout: Create your portfolio in minutes with a single shareable page.
- Larpable: Spot fake founders, guru grifts, and performance entrepreneurship.
- Doved Studio: Studio indie derrière cette app et une dizaine d'autres outils.
ralph
Building tools for better AI outputs. Ralphable helps you generate structured skills that make Claude iterate until every task passes.