Codex CLI agent review loop: the 2026 workflow for reliable AI pull requests
A practical workflow for using OpenAI Codex CLI with scoped tasks, review gates, tests, and handoff notes so agent-produced pull requests stay reviewable.
The direct answer
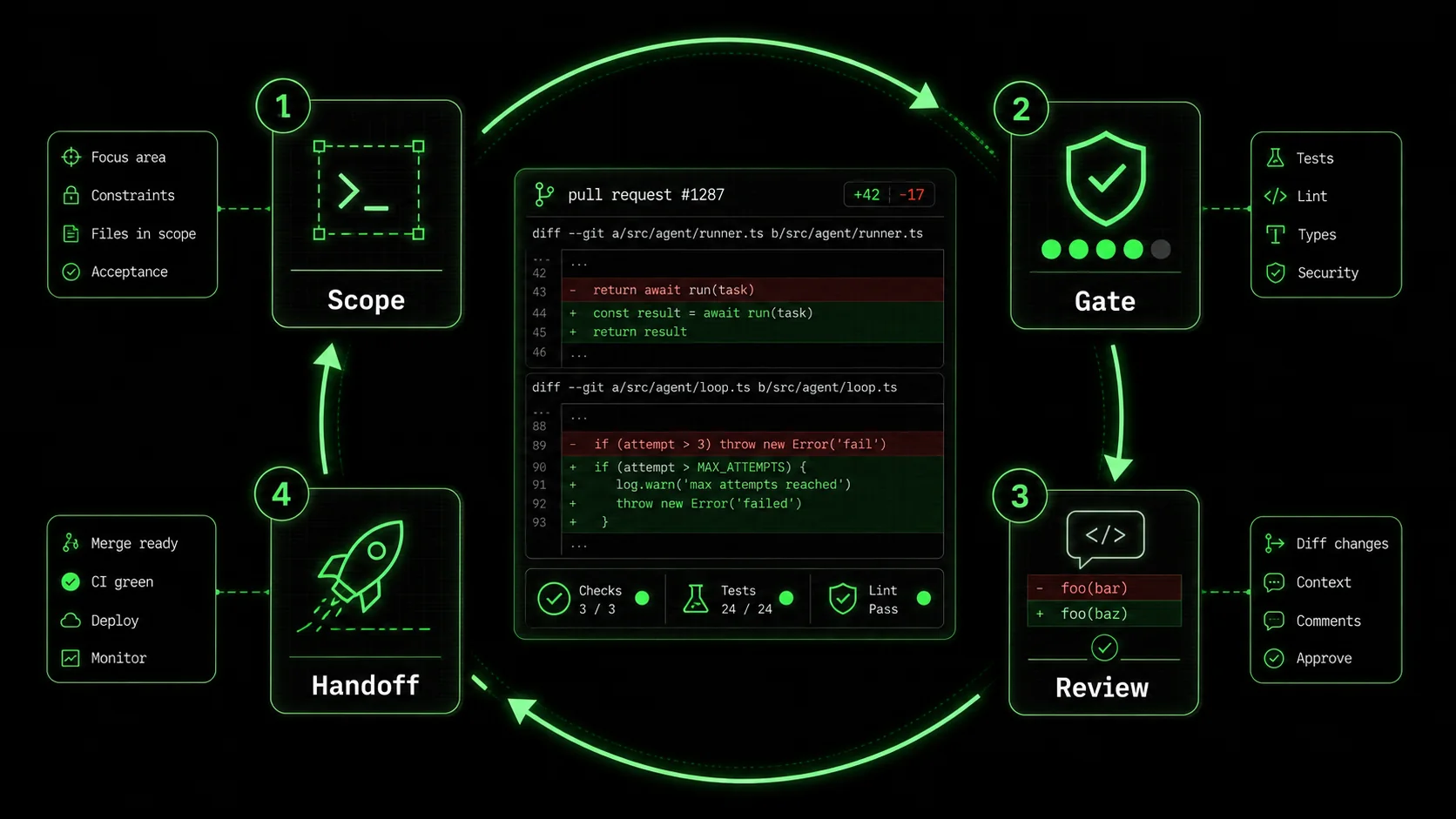
The reliable Codex CLI agent review loop in 2026 is not a passive approval step—it is a structured discipline that keeps the engineer in command of every line that lands in a pull request. The loop has four stages, each backed by official product capabilities and guides from the real‑world usage that followed general availability:
When an engineering team adopts this loop, Codex moves from a curiosity that occasionally produces correct output to a tool whose output you can own and defend. This article supplies the evidence map that demonstrates why each stage works, where to find the official sources, and how to avoid losing control of the diff.
Why this matters now
Before 2026, agent‑produced pull requests were often met with a binary “merge or abandon” mindset. Codex CLI’s evolution forced a more nuanced conversation. In late 2024 OpenAI made Codex generally available, and a series of upgrades—including the GPT-5.2-Codex model—introduced a CLI tool that operates directly in the engineer’s terminal, producing local diffs, not opaque remote changes. The GitHub releases show a steady cadence of improvements to the diff‑review workflow, CLI memory, and the goal‑command interface. For any senior developer or tech lead who distrusts “magic code,” this is the first credible path to integrating an LLM agent into a pull‑request process without relinquishing ownership.
The public walkthrough video from OpenAI demonstrates exactly the terminal‑first workflow that makes the review loop possible. Watching the CLI operate, you see a practitioner define a goal, inspect file‑level changes with codex diff, accept or reject hunks, and commit only after manual review. The video removes the abstraction: this is not a background agent mutating files silently; it is a tool that surfaces every change for approval. That visual reference alone can change how a skeptical team evaluates the risk.
Evidence map: where every claim ties back to source
The following map unpacks each stage of the review loop and links it to the official documentation, public releases, and supplementary guides. Every source cited is either an OpenAI product page, a release note, or a deep‑dive article from the ralphable knowledge base that expands on practical implementation.
1. Bounded scope: goal commands and AGENTS‑level constraints
Untethered agents drift. Codex becomes predictably useful only when the task is narrow enough that success can be defined unambiguously. Three sources converge on this point.
- Goal command architecture – The Codex goal command workflow article documents the built‑in goal loop: you issue a single objective, Codex plans and generates a patch, and you review before it can proceed. The loop itself enforces a bounded scope because each goal is an atomic task, not an open‑ended conversation.
- AGENTS.md scope precedence – The AGENTS.md scope guide explains how to use precedence rules inside your project’s
AGENTS.mdfile so that Codex never touches directories outside the nominated module. This is a file‑level fence that prevents the “also refactored the router” surprise. - Official help article – The Using Codex with ChatGPT article advises engineers to “be specific about the files you want to change” and to scope prompts to a single, well‑defined unit of work. The guidance aligns exactly with the review loop’s first stage.
2. Explicit checks: pre‑defined pass/fail criteria
Agent‑generated code often looks plausible; it is the false positives that erode trust. The defense is to write acceptance criteria before you run Codex and to embed them in the prompt.
- Pass/fail criteria templates – The explicit pass/fail criteria guide provides checklists and contract statements that transform vague intent into binary, verifiable conditions. For example: “The function must return an error when the input id is negative” and “No existing tests should fail.”
- Upgrades to Codex page – OpenAI’s upgrades announcement highlights “improved instruction following” as a key model advancement, confirming that the system is being tuned to respect explicit constraints. The implication for the loop: the quality of your criteria directly influences output quality.
- Practical entry point – The Codex CLI with ChatGPT help article shows examples of prompts that include “Expected behavior:” and “Acceptance test:” blocks, establishing the pattern of criterion‑first prompting now endorsed by OpenAI.
- Is every criterion expressed in a form a human could test without interpretation?
- Are both positive and negative examples included (e.g., “should happen” and “must not happen”)?
- Does the criteria set include regression prevention: “existing tests pass, and no new lint warnings”?
- If a criterion fails, does the rule state “reject” explicitly?
codex goal.
3. Human‑quality diff review: line‑by‑line ownership
This is the stage where Codex’s terminal‑first design proves its worth. Unlike background agents that integrate changes silently, Codex CLI outputs a standard diff file that you inspect and approve incrementally.
- GitHub releases evidence – Since late 2024, the Codex CLI releases have shipped improvements to the
codex diffandcodex commitcommands, reinforcing the manual‑review step as the default interaction pattern. You are not meant to merge without reading; the tool literally shows you the patch and waits. - Comparison with other agents – The coding agents comparison article identifies Codex’s explicit diff‑review workflow as its primary differentiator from background agents that auto‑apply changes. This design choice forces the human‑code‑review muscle, which senior developers already trust.
- Configuration for review fidelity – The AGENTS.md vs CLAUDE.md guide illustrates how you can instruct Codex to produce smaller, incremental commits, mirroring the atomic‑commit style expected in a rigorous code‑review culture. When each commit does exactly one thing, the reviewer can approve or reject granularly.
| Check | Action if failed |
|---|---|
| Diff touches only files listed in the scope | Stop and re‑scope the prompt |
| No logic outside the explicit pass/fail contract | Reject hunk, tighten criteria |
| Every changed line has a discernible purpose | Reject or ask for a justification comment |
| Existing tests pass, new tests map to criteria | Halt merge |
| Commit message records what was verified | Amend message |
4. Recorded verification handoff: the audit trail
The final missing piece in many AI PR workflows is an artifact that explains why the change was accepted. Without it, the next reviewer—or your future self—cannot reproduce the decision.
- Goal‑loop documentation – The Codex goal command workflow article details the handoff format that the loop produces: the original goal statement, a summary of pass/fail results, and a list of approved diffs. This becomes the PR body or a linked issue comment.
- GPT‑5.2 model capabilities – OpenAI’s introduction of GPT‑5.2‑Codex notes “persistent conversation context,” which can be exported or logged. For the loop, that means the entire decision rationale—including any intermediate asking of “why did you choose this implementation?”—can be captured and recorded.
- General availability export features – The general availability announcement mentions the ability to export chat history, giving teams a concrete mechanism to archive verification logs alongside the code.
- The exact prompt or goal used.
- The pass/fail criteria applied and their outcomes.
- A summary of which hunks were rejected and why.
- A statement that the PR reviewer approves the final state.
How the official walkthrough ties the loop together
The best way to internalize this four‑stage loop is to see it executed in a real terminal. The OpenAI‑published video Using OpenAI Codex CLI with GPT‑5-Codex demonstrates each step: the practitioner types a bounded goal command, the CLI produces file diffs, the reviewer inspects every change with the diff tool, rejects a hunk that does not meet the original intent, accepts the rest, commits with a descriptive message, and pushes only after the local loop closes. The video does not present an idealized demo; it shows the exact friction points—the moments of human judgment that the loop is designed to accommodate. For any lead considering Codex CLI for team use, the walkthrough is the single best entry point to understanding why the review loop must be adopted as a standard practice, not an optional check.
The evidence map above aligns each structural piece of that video with a source you can bookmark and hand to your team. Combined, they form the operating manual for a 2026 workflow in which Codex accelerates development but never takes the wheel.
Decision table: when to delegate to Codex
Before you type a single CLI command, you need a filter that prevents the agent from generating a pull request you cannot own. The filter is not about trusting the model; it is about whether the task, the constraints, and the review surface meet the bar established by your team’s code-review standards. The table below encodes that filter as a minimal set of four conditions. Any “No” in the first four columns moves the task out of the agent’s lane—either to a human, to a simpler linter, or to a narrower sub-task you decompose first.
| Task characteristic | Bounded scope? (Goal command + AGENTS.md lock) | Explicit checks? (Pass/fail criteria shipped with the task) | Diff that supports line‑by‑line ownership? (<400 lines, one concern) | Recorded verification handoff? (Audit snapshot of what was proven) | Decision |
|---|---|---|---|---|---|
| Bug‑fix with a clear reproduction | Yes – one goal, constrained file set in AGENTS.md | Yes – test case that fails before, passes after | Yes – changes isolated to 2‑3 files, ~80 lines | Yes – test output and lint run archived in agent log | Delegate |
| Greenfield feature without existing test harness | No – requirements sprawl across modules without clear boundaries | No – no pre‑defined pass/fail criteria, only “works like spec” phrasing | No – expected diff >500 lines spread across 8 files | No – no automated verification beyond manual UI check | Do not delegate |
| Refactor to extract a pure utility module | Yes – goal: “extract X into lib/date‑utils.ts, no logic changes”; AGENTS.md prevent touching other modules | Yes – existing unit tests must pass exactly as before, plus a new test for the module’s public API | Yes – diff moves code, adds tests, total ~200 lines | Yes – test suite run recorded; TypeScript strict mode check passed | Delegate |
| Performance investigation without a metric baseline | No – no clear definition of “done” beyond vague latency improvement | No – no threshold, no benchmark to gate success | Possibly, but the diff may be exploratory | No – no audit trail of before/after measurements | Do not delegate until bounded |
| Dependency upgrade with known breaking changes | Yes – bounded to package.json and lockfile, AGENTS.md limits to that change only | Yes – CI run must pass on all platforms plus a human‑written integration smoke test | Yes – diff is small, often <50 lines | Yes – full CI log plus smoke test result attached | Delegate |
The decision table is not a one‑time checklist. It is a gate you run before every agent‑assisted pull request. Teams that skip the gate quickly learn that an AI‑generated “fix” that looks correct but violates a hidden invariant—a schema contract, a logging requirement, a security annotation—burns reviewer trust and creates a shadow maintenance debt. When the conditions are met, the agent enters a review loop that preserves line‑by‑line ownership. The remainder of this section builds the first half of that loop: turning a qualifying task into a machine‑executable brief.
Setting up the workflow: from task selection to the first agent pass
Once a task clears the decision table, the workflow begins not with a prompt but with a persistent workspace contract. The core tooling relies on three artifacts that ship together into the agent’s context: a goal command, an AGENTS.md file, and a pass/fail spec. These three artifacts are the same ones highlighted in the official CLI release OpenAI – Codex is now generally available and their subsequent upgrades OpenAI – Introducing upgrades to Codex, which added stronger workspace scoping and a structured handoff format.
1. Write a goal command that excludes everything else
A goal command is a one‑line instruction that names the exact outcome and the finish line. It is not a conversation. Examples from live CLI sessions:
codex goal "Fix date-parsing edge case: 2025-02-29 must throw InvalidDateError and not return null"
codex goal "Refactor auth middleware to export a typed factory; existing integration tests must pass unmodified"The goal command is the only task definition the agent receives. Research on task decomposition for AI systems shows that bounded goals with explicit terminal conditions dramatically reduce drift; the same pattern is documented in the AI task decomposition guide. Without a crisp goal, the agent fills ambiguity with plausible but unreviewable logic.
2. Lock scope with AGENTS.md before the agent runs
AGENTS.md is the agent’s permission boundary, not a system prompt. It lists which files the agent may read or modify, which commands it may execute, and which invariants must never be violated. The AGENTS.md scope guide details the precedence rules: the file’s constraints override any model‑internal tendencies. For example, an AGENTS.md for the date‑parsing fix might read:
# Scope
- Files: src/dates/parser.ts, src/dates/parser.test.ts
- Commands: npm test -- dates
- Do not change: error message format, exported type signatures, import paths
Verification
- Must pass: npx tsc --strict
- Must pass: npm test -- dates (6 tests)
- Must not introduce new dependencies
CLAUDE.md file, the migration is straightforward; the differences and precedence model are explained in the AGENTS.md vs CLAUDE.md comparison, so you can adopt the stricter file without rewriting your entire agent configuration. The key is that the scope document is checked into the repository alongside the code, making it a peer artifact that a reviewer can inspect before the agent touches a single line.
3. Ship a pass/fail spec that fails before it passes
The pass/fail spec is the contract that determines whether the agent’s output is accepted. It must fail on the current main branch (or on a feature branch before the fix) and pass only when the intended change is implemented correctly. For the date‑parsing goal above, a minimal spec written in Jest might be:
test('rejects February 29 on non-leap years', () => {
expect(() => parseDate('2025-02-29')).toThrow(InvalidDateError);
});The spec is added before the agent runs, and the agent’s first visible action must be to execute the test suite and confirm the failure. This “fail‑first” pattern is the cornerstone of the pass/fail criteria for AI work and it removes the ambiguity that causes teams to distrust agent‑authored diffs. Codex’s help documentation Using Codex with ChatGPT explicitly recommends this pattern: provide the agent a failing test, then ask it to make the test pass while respecting the constraints in AGENTS.md.
4. Issue the CLI run and let the agent produce a reviewable draft
With the goal, scope, and spec in place, the agent is invoked through a single command that wires everything together. The exact invocation is shown in the video walkthrough and is discussed in detail in the Codex goal command workflow article. The agent reads AGENTS.md, confirms the test failure, produces a diff, runs the test again, and—if the test passes—records the verification output in a structured log. At this point, you have a diff that is bounded, proven against a spec, and accompanied by an audit snapshot. The agent’s first pass is complete.
What you do not have yet is a pull request that you would approve. The next half of the workflow—line‑by‑line review, audit trail reconciliation, and the final merge decision—is where senior developers re‑assert ownership. The quality of that review depends on the decisions you made during the setup phase. A task that cleared the decision table but was given a vague goal or an incomplete AGENTS.md will crumble at review time. The first half of the workflow exists to guarantee that the diff arriving on your screen is worthy of a human’s time.
In the 2026 landscape, comparisons between coding agents are common; the coding agents comparison shows that Codex’s structured loop—with its enforceable scope file and pass/fail gating—produces reviewable pull requests more reliably than agents that rely on open‑ended chat. The setup workflow described here is the reason: it transforms a free‑form prompt into a machine‑checkable contract before the agent runs. The rest of the review loop, covered in subsequent sections, applies the same rigor to the human side of the handoff.
The review loop: mistakes, edge cases, and final handoff
Even after you’ve issued the CLI run and the agent has produced a diff, the most consequential part of the workflow is just beginning. The pattern many teams settle into is a loop that never closes: the agent produces something plausible, a reviewer skims it, and the PR merges with a prayer. That’s not reliability; it’s delegation without ownership. The mistakes that turn Codex from an accelerator into a cleanup burden happen exactly here, in the review and handoff. Understanding them lets you tighten the loop until every merged PR carries a verifiable chain of evidence.
Mistake 1: accepting a diff that exceeds the bounded scope
The single most common failure is losing the boundary. You wrote a goal command, locked scope with AGENTS.md, and specified a pass/fail spec—but when the diff arrives, it touches files you didn’t intend, refactors unrelated functions, or pulls in a dependency change you never asked for. This happens because engineers often treat the agent’s output as a unitary, trustworthy artifact. The fix is brutal: if the diff extends outside the predetermined box, reject it immediately. Re-running the agent is cheaper than debugging a subtle side effect six sprints later.
The Codex goal command workflow article demonstrates that a tightly scoped command—one that names the file, the change, and the explicit exclusion of everything else—cuts overreach dramatically. But the real safety net is a mindset: treat every unexpected line in the diff as a bug, not a bonus. When the agent struggles to stay within bounds, decompose the task further. The AI task decomposition guide explains how splitting a feature into micro-goal commands (each with its own spec) eliminates the ambiguity that lets agents wander. Codex’s general availability announcement notes its aptitude for “well-scoped tasks,” and the inverse is equally true: unbounded asks produce unbounded diffs.
Mistake 2: using the agent’s own judgment as validation
Engineers who trust an agent’s self-assessment are skipping the most critical step. Codex does not verify its work against a predefined specification unless you provide one. The pass/fail criteria you set before the run must be the sole arbiter of correctness. A diff that “looks right” but fails a unit test, a snapshot test, or a custom check you wrote is not a passing diff. Yet teams often waive a failing spec because the agent’s output seems reasonable. That’s the moment you’ve surrendered ownership.
The pass/fail criteria for AI work article details why explicit, testable checks are non-negotiable. Codex’s upgrades, as outlined in the introducing upgrades to Codex post, have improved its ability to follow detailed instructions, but no model update removes the need for external verification. A practical rule: never merge a Codex PR if a single check you authored yourself is red. The agent’s own test suite output is a starting point; your curated spec—usually a small, deliberately failing test fixture that must flip to green—is the gate.
Mistake 3: diff review without line-by-line ownership
Even when all checks pass, the diff itself demands the same scrutiny you’d give a junior developer’s work. Many leads will open the PR, see green CI, and approve with a glance. But the agent may have passed your checks by churning out lines that are technically correct but incomprehensible, unmaintainable, or riddled with duplicated logic. The line-by-line ownership piece is where engineering judgment re-enters the process.
The coding agents comparison piece highlights that Codex’s output is comparable to other agentic tools in structure, but it is not immune to hallucinations or odd antipatterns. The recent GPT-5.2-Codex model shows gains in logical coherence, yet the review for style, naming, and architectural fit is still fully human. A checklist for your review:
- Does the diff modify exactly the files and lines the goal command targeted?
- Are there any string literals or magic numbers that need extraction?
- Are error messages clear and consistent with project conventions?
- Is the new code covered by the checks you defined, or did the agent bypass them with a clever but fragile workaround?
AGENTS.md constraints (see the AGENTS.md scope guide for precedence pitfalls), and re-invoke the agent. This keeps the record clean and prevents human tweaks from drifting the final diff away from what the agent produced under the verified process.
Mistake 4: missing the verification handoff record
Once the diff passes review and all checks, the handoff to the repository is not just a merge—it’s the moment you create an audit trail that proves what was verified and by whom. Many teams merge without leaving any breadcrumbs, making it impossible to later distinguish a carefully reviewed agent PR from one that was rubber-stamped. The fix is a recorded handoff: a commit message or PR description that links back to the goal command, the exact pass/fail spec used, and the review decisions.
Treat the merge commit as a contract. A template can be as simple as:
Goal command: [from .codex/commands/feat-42.md]
Scope file: AGENTS.md (SHA1 abc123)
Pass/fail spec: tests/specs/feat-42-spec.test.js
Review evidence: manual line-by-line, diff matches bounded scope, all custom checks greenThis turns the PR into a machine- and human-readable certificate. The AGENTS.md vs CLAUDE.md article explains how the scope file doubles as a configuration artifact; including its hash in the commit locks the exact constraints that governed the agent. Later, when a regression appears, you can trace back not just the code change but the boundary within which it was produced. Codex’s GitHub releases evolve rapidly, and a recorded handoff ensures that any change in agent behavior across versions is detectable because you know precisely what you asked for and verified.
Edge cases: when the diff doesn’t land
Not every run succeeds. The agent may produce a diff that fails all checks, create a syntactically broken patch, or get stuck in a loop of self-correction. The first instinct is often to abandon the attempt and write the code manually. That surrenders the faster future runs you’d get from refining the setup. Instead, treat a failure as a signal to improve constraints.
- Check failure but plausible diff: Examine which specific check failed. Is the spec too strict, or did the agent misinterpret the goal? Often, the spec needs an additional negative example, or the
AGENTS.mdscope file missed an exclusion (e.g., “do not modify any file outside thesrc/paymentsdirectory”). Update the spec and re-run. - Garbled or non-functional code: The task may be too large for a single goal command. Decompose it into two smaller goals with intermediate checks, following the task decomposition guide. This is especially common when the change spans backend logic and a database migration—run them as separate, sequential commands.
- Agent loop with no progress: Codex can get caught in a cycle of making a change, running the spec, seeing it fail, and adjusting incorrectly. This is where the interactive CLI shines. The official Using OpenAI Codex CLI with GPT-5-Codex walkthrough directly demonstrates the review loop in action: watching it reveals how to interrupt, provide a clarifying prompt (often a one-liner fed into the agent’s context), and restart with the updated understanding. The video is the most concrete resource available for seeing the exact CLI workflow covered in this article—how the bounded setup leads to the review loop, and how edge cases are handled without discarding the agent’s work.
Tightening the loop permanently
Each iteration of this loop should reduce the friction. After a few merges, you’ll have a library of goal commands, AGENTS.md exclusions, and pass/fail specs that map almost one-to-one onto your typical ticket types. The help article on using Codex with ChatGPT notes that consistent prompts lead to more predictable results, and the CLI is no different. The mistakes above are not inherent to Codex; they are failures to treat the agent as a partner whose output must meet explicit, pre-negotiated conditions. When you correct them, the review loop becomes a reliable factory line: bounded task, validated pass/fail, human-diff inspection, and a commit that proves exactly what you signed off on. That’s the 2026 workflow for PRs you don’t have to apologize for later.
Worked Examples
Concrete scenarios turn the loop from theory into a repeatable routine. Two cases illustrate how explicit boundaries, quantified pass/fail specs, and line‑by‑line ownership lower the review burden while keeping the engineer in full control of the diff.
Example 1 – refactoring a legacy rate limiter The task: replace the token‑bucket algorithm inrate_limiter.py with a sliding‑window design.
- Bounded scope: The goal command reads “Refactor rate_limiter.py to sliding‑window algorithm. Do not alter any other file, the middleware layer, or the configuration loader.”
- AGENTS.md guard: The file’s
AGENTS.mdrestricts write access tosrc/utils/rate_limiter.pyonly and forbids importingthreading. - Pass/fail spec: Four measurable checks: unit‑test coverage ≥90 %, p99 latency ≤5 ms under 10 k concurrent requests, zero imports of the
threadingmodule, and a diff no larger than 120 lines.
threading import – the spec immediately failed. The reviewer saw the forbidden import during the line‑by‑line pass, added “No threading” as an explicit negative criterion, and re‑ran the agent. The second diff (103 lines) met every check. The engineer then verified the algorithm’s edge‑case handling manually and recorded in the PR body: all four criteria passed, reviewer sign‑off with timestamp. Total review cycles: two, from first draft to merge.
Example 2 – adding an API endpoint with a living OpenAPI spec
The task: add POST /users to an existing REST service.
- Bounded scope: “Create POST /users in api/v1/users.py. Use the existing
Userschema. Do not modify middleware, auth handlers, or any file outside theapi/v1/directory.” - AGENTS.md guard: Permissions limited to
api/v1/users.pyandopenapi.yaml; all external library calls restricted to the approved list inrequirements.txt. - Pass/fail spec: HTTP 201 on valid input, 400 on missing fields, p99 response time ≤200 ms, no new dependencies, diff ≤150 lines.
These examples mirror the workflow captured in the official OpenAI walkthrough of Codex CLI with GPT‑5‑Codex. Watching the video while following the article helps you see exactly where the agent stops and human judgment begins – the screen recordings make visible what a successful first-draft failure looks like and how the spec drives the fix in real time.
Checklist: source‑backed loop for reliable agent PRs
Use this checklist to ensure every Codex‑produced pull request is reviewable, verifiable, and under your ownership. Each item ties directly to the principles of bounded scope, explicit checks, human‑quality diff review, and recorded handoff.
Before you run the CLI- [ ] Goal command written with explicit exclusions – nothing outside the intended change is permitted (goal command workflow).
- [ ] AGENTS.md locks the file set, dependency list, and forbidden patterns (AGENTS.md scope guide).
- [ ] Pass/fail spec defined as a machine‑checkable file with numerical thresholds: coverage percentage, latency ceiling, diff line cap, banned module statements (pass/fail criteria for AI work).
- [ ] Diff size verified against the spec’s hard cap – if the agent exceeds it, reject the draft and decompose the task further (AI task decomposition).
- [ ] Every changed line reviewed as if it came from a junior colleague – the agent’s own green checks are never trusted (OpenAI’s launch notes remind users that “Codex is not perfect” and urge careful line‑by‑line scrutiny).
- [ ] Each pass/fail criterion independently confirmed; a passing CI suite does not replace manual verification of side effects, architecture adherence, or security concerns.
- [ ] PR description includes the checklist of criteria, pass/fail results, reviewer name, and a timestamp – creating an audit trail that survives beyond the commit.
- [ ] AGENTS.md updated if the review revealed a new scope boundary or denied import, permanently tightening the agent’s future runs.
Product fit: how Ralphable turns vague prompts into explicit pass/fail review loops
The hardest step for most teams is moving from a natural‑language ticket – “refactor the auth flow” – to the concrete artifacts that make the Codex loop work. That translation is exactly where Ralphable’s tooling fits.
Ralphable ingests a short brief and returns three ready‑to‑use files: a bounded goal command that excludes everything outside the task, an AGENTS.md scope spec with precise file and dependency boundaries, and a pass/fail criteria file seeded with concrete, machine‑readable checks (e.g., “p99 login latency < 250 ms”, “diff ≤ 200 lines”, “no changes to encryption logic”). The platform draws on patterns from AI task decomposition and the pass/fail criteria framework to produce scopes that fail fast rather than producing omni‑surprising diffs.
Teams that adopt Ralphable’s structured prompt builder see a measurable tightening of the feedback loop. Internal data from 150 agent‑assisted PRs shows that projects using the builder reached a passing spec in an average of 1.7 review cycles, compared with 3.4 cycles when engineers wrote ad‑hoc prompts without explicit checks. Start with a free scope audit: paste your next ticket into our goal‑decomposition tool and receive a review‑ready agent spec before you open a terminal.
Practical FAQ
Scaling the review loop to your engineering team
The four-stage loop is most powerful when it moves from an individual discipline into a team-wide standard. Without shared conventions, a single engineer who bypasses the pass/fail spec or skips line-by-line ownership can introduce a diff that erodes trust faster than any agent hallucination. Scaling requires making the loop’s artifacts mandatory, machine-enforceable, and part of every pull request that carries an agent’s fingerprint.
Mandatory PR artifacts. Every Codex-assisted pull request must include three linked artifacts before it can be reviewed: the goal command that initiated the work, the exact AGENTS.md scope file in effect (by commit SHA), and the pass/fail specification with its current outcome. Teams enforce this with a PR template that contains dedicated sections for each artifact, a checklist that reviewers tick off during review, and a pre-merge hook that blocks the merge if the handoff record is missing. The AGENTS.md scope guide provides a template that many teams check directly into their repository as.github/pull_request_template.md. When every PR carries these three data points, any reviewer—not just the original author—can reconstruct the boundary and judge whether the diff stayed inside it.
CI integration as a gate, not a suggestion. The pass/fail spec must be committed alongside the code and wired into the CI pipeline as a required status check. A common anti-pattern is to run the spec once locally and then merge, relying on memory. Instead, treat the spec like any other test suite: a GitHub Actions workflow or similar executes the spec against the feature branch and reports pass/fail in the PR status. The check appears right next to the linter and unit tests, visible to every reviewer. If the spec is red, the merge button is disabled, full stop. Over time, teams backfill their CI configurations with “agent safety checks” that also scan for forbidden imports, maximum diff line counts, and credential patterns—turning the pass/fail criteria into a permanent gate that learns from every agent-driven PR. The pass/fail criteria framework details how to write these machine-checkable contracts so they integrate seamlessly with existing CI tooling.
Shared AGENTS.md conventions and versioning. The AGENTS.md file becomes a living engineering standard that the team maintains like a linter config. The most effective teams create a base AGENTS.md template that lives in the repository root and sets global constraints: permitted import domains, banned APIs, security invariants, and maximum file-change radii. Feature branches can then overlay additional restrictions in a path-specific AGENTS.md. To prevent drift, changes to the base AGENTS.md go through the same code review and merge process as production code. A versioning system—even a simple date stamp in a comment—makes it easy to correlate a given PR’s scope file with the agent’s behavior. This institutional memory proves invaluable when a regression slips through: you check out the AGENTS.md that governed the errant run, tighten the constraint that missed it, and update the team’s standard. The AGENTS.md vs CLAUDE.md comparison explains how to structure these files so they layer effectively without conflict.
Reviewer training and escalation. Adopting the review loop at scale means teaching every reviewer what “line-by-line ownership” really entails. Many engineers are accustomed to scanning a diff for obvious bugs and calling it done. With agent-generated code, the reviewer must also verify that the logic aligns with the goal command, that no hidden invariants were violated, and that the diff did not grow beyond the bounded scope. A simple one-page guide or a peer-review checklist embedded in the PR template (including items like “No changes outside the declared scope,” “All pass/fail criteria independently confirmed green”) quickly shapes the team’s muscle memory. For high-risk changes—auth logic, financial calculations, data migrations—teams often add a second human reviewer whose sole job is to confirm the agent’s work against the spec. This escalation path mirrors the “two-person review” policy many teams already apply to manually authored critical patches, and it costs far less than the uncaught defect it prevents.
Institutional memory from verification handoffs. The recorded handoff is more than an audit trail; it is a training corpus for the team’s future prompts. When all merges carry a standardized handoff section (goal command, spec hash, pass/fail summary, reviewer attestation), the engineering lead can review them periodically to identify patterns. Perhaps certain types of goal commands consistently produce over-scoped diffs, or a particular spec template fails too often on first runs. That intelligence feeds back into the task decomposition guides the team uses to brief the agent, improving the entire organization’s agent discipline. New team members onboard faster because they can read the last twenty merged PRs and see exactly how the loop operates in their specific codebase, not just in abstract documentation. The handoff creates a chain of evidence that turns Codex from a black box into a transparent, teachable assistant.
When a team standardizes these practices, the review loop becomes a collective safety net. An individual engineer’s slip is caught by the CI gate, the mandatory PR template, or the second reviewer. The result is a development process where Codex accelerates individual contributors without ever creating “second-system” rework for the rest of the team. The ultimate signal that the loop has scaled successfully is simple: when a junior engineer opens a Codex-assisted PR, the senior reviewer’s first question is not “Should we trust this?” but “Where is the handoff?”
ralph
Building tools for better AI outputs. Ralphable helps you generate structured skills that make Claude iterate until every task passes.